![]()
[1]:
#!pip install tensorflow==2.7.0
#!pip install scikeras
Subclassing for GCCE¶
[2]:
!git clone https://github.com/Jectrianama/GCCE_TEST.git
Cloning into 'GCCE_TEST'...
remote: Enumerating objects: 684, done.
remote: Counting objects: 100% (277/277), done.
remote: Compressing objects: 100% (150/150), done.
remote: Total 684 (delta 151), reused 215 (delta 122), pack-reused 407
Receiving objects: 100% (684/684), 31.03 MiB | 16.50 MiB/s, done.
Resolving deltas: 100% (319/319), done.
[3]:
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import numpy as np
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
[4]:
import os
os.chdir('/content/GCCE_TEST/Models')
from keras_ma_gcce import *
from labels_generation import MA_Clas_Gen
os.chdir('../../')
[5]:
#cargar datos desde drive otros dataset
FILEID = "1AU8pTtCLihBjCZjWITaAzpnEuL4RO436"
#https://drive.google.com/file/d/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O DataGCCE.zip && rm -rf /tmp/cookies.txt
!unzip -o DataGCCE.zip
!dir
--2023-02-11 05:40:39-- https://docs.google.com/uc?export=download&confirm=&id=1AU8pTtCLihBjCZjWITaAzpnEuL4RO436
Resolving docs.google.com (docs.google.com)... 142.250.4.139, 142.250.4.100, 142.250.4.102, ...
Connecting to docs.google.com (docs.google.com)|142.250.4.139|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ra1l9levhfqg6nhjcoc70qjrgb909ebh/1676094000000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=d1fccb0f-7a34-4e0b-b55a-e6eebbc04b59 [following]
Warning: wildcards not supported in HTTP.
--2023-02-11 05:40:39-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ra1l9levhfqg6nhjcoc70qjrgb909ebh/1676094000000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=d1fccb0f-7a34-4e0b-b55a-e6eebbc04b59
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 74.125.130.132, 2404:6800:4003:c01::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|74.125.130.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 38377 (37K) [application/x-zip-compressed]
Saving to: ‘DataGCCE.zip’
DataGCCE.zip 100%[===================>] 37.48K --.-KB/s in 0s
2023-02-11 05:40:40 (77.1 MB/s) - ‘DataGCCE.zip’ saved [38377/38377]
Archive: DataGCCE.zip
inflating: new-thyroid.csv
inflating: tic-tac-toe-endgame.csv
inflating: balance-scale.csv
inflating: file.csv
balance-scale.csv file.csv new-thyroid.csv tic-tac-toe-endgame.csv
DataGCCE.zip GCCE_TEST sample_data
[6]:
#cargar datos desde drive acceso libre
FILEID = "1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW"
#https://drive.google.com/file/d/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O MADatasets.zip && rm -rf /tmp/cookies.txt
!unzip -o MADatasets.zip
!dir
--2023-02-11 05:40:40-- https://docs.google.com/uc?export=download&confirm=t&id=1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW
Resolving docs.google.com (docs.google.com)... 142.250.4.139, 142.250.4.100, 142.250.4.102, ...
Connecting to docs.google.com (docs.google.com)|142.250.4.139|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/4tgeilqntork48kn93kv1p84uju2gj0v/1676094000000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=f1653d0d-0bec-4b54-93ae-d781d61b65be [following]
Warning: wildcards not supported in HTTP.
--2023-02-11 05:40:41-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/4tgeilqntork48kn93kv1p84uju2gj0v/1676094000000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=f1653d0d-0bec-4b54-93ae-d781d61b65be
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 74.125.130.132, 2404:6800:4003:c01::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|74.125.130.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 156530728 (149M) [application/zip]
Saving to: ‘MADatasets.zip’
MADatasets.zip 100%[===================>] 149.28M 38.3MB/s in 3.9s
2023-02-11 05:40:45 (38.3 MB/s) - ‘MADatasets.zip’ saved [156530728/156530728]
Archive: MADatasets.zip
inflating: MADatasets/util.py
inflating: MADatasets/Iris1.mat
inflating: MADatasets/Integra_Labels.mat
inflating: MADatasets/MAGenerationClassification.py
inflating: MADatasets/Voice.mat
inflating: MADatasets/Iris.mat
inflating: MADatasets/Sinthetic.mat
inflating: MADatasets/MAGenerationClassification_1.py
inflating: MADatasets/Bupa1.mat
inflating: MADatasets/TicTacToe1.mat
inflating: MADatasets/Wine.mat
inflating: MADatasets/Breast1.mat
inflating: MADatasets/Breast.mat
inflating: MADatasets/Music.mat
inflating: MADatasets/Pima.mat
inflating: MADatasets/Ionosphere.mat
inflating: MADatasets/TicTacToe.mat
inflating: MADatasets/VoiceData.m
inflating: MADatasets/util_1.py
inflating: MADatasets/Ionosphere1.mat
inflating: MADatasets/__pycache__/util_1.cpython-37.pyc
inflating: MADatasets/Bupa.mat
inflating: MADatasets/Wine1.mat
inflating: MADatasets/__pycache__/util.cpython-37.pyc
inflating: MADatasets/Pima1.mat
inflating: MADatasets/Segmentation1.mat
inflating: MADatasets/Western.mat
inflating: MADatasets/Integra_Preprocesamiento_Seg_Caracterizacion_time_frec.mat
inflating: MADatasets/Western1.mat
inflating: MADatasets/Segmentation.mat
inflating: MADatasets/Skin_NonSkin.mat
inflating: MADatasets/Skin_NonSkin1.mat
inflating: MADatasets/Occupancy1.mat
inflating: MADatasets/Polarity.mat
inflating: MADatasets/Occupancy.mat
balance-scale.csv GCCE_TEST new-thyroid.csv
DataGCCE.zip MADatasets sample_data
file.csv MADatasets.zip tic-tac-toe-endgame.csv
Load Data¶
[7]:
#load data
import scipy.io as sio
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf #importar tensorflow
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import numpy as np
database = 'Balance' #['bupa1', 'breast-cancer-wisconsin1','pima-indians-diabetes1', 'ionosphere1', 'tic-tac-toe1', 'iris1', 'wine1', 'segmentation1']
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv(r'/content/balance-scale.csv')
df.head()
#Dividing X and y
t = np.array(LabelEncoder().fit_transform(df['Class'].tolist()))
X = np.array(df.drop(['Class'], axis = 1).values)
print('X',X.shape,'t',t.shape)
t = t+1
t
X (625, 4) t (625,)
[7]:
array([1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 2, 1, 3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 2, 2, 1, 3, 3, 2, 3, 3, 3, 3, 1, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 2, 1, 3, 2, 1, 3, 3, 3, 2, 3, 3,
3, 3, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 2, 2, 1, 2, 2, 3, 3, 3,
2, 3, 3, 3, 3, 2, 3, 3, 3, 3, 1, 3, 3, 3, 3, 2, 1, 3, 3, 3, 1, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 2, 1,
3, 2, 1, 3, 3, 3, 2, 3, 3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2,
2, 2, 2, 2, 2, 2, 1, 3, 3, 2, 1, 3, 3, 3, 2, 3, 3, 3, 3, 2, 3, 3,
3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 1, 3, 2, 2, 3, 3, 3, 2, 1, 3, 3, 3,
2, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 3, 3, 2, 2,
3, 3, 3, 2, 1, 3, 3, 3, 2, 2, 1, 3, 3, 2, 3, 3, 3, 3, 1, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 1, 3, 3, 2,
1, 3, 3, 3, 2, 3, 3, 3, 3, 2, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2,
2, 3, 2, 2, 1, 3, 3, 2, 2, 3, 3, 3, 2, 3, 3, 3, 3, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 1, 3, 2, 2, 1, 3, 3, 2, 2, 3, 3, 3, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 3, 3, 2, 2, 1, 3,
3, 2, 2, 2, 1, 3, 2, 1, 3, 3, 3, 2, 3, 3, 3, 3, 1, 3, 3, 3, 3, 3,
3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 1, 3, 2, 2, 3, 3, 3, 2, 1, 3,
3, 3, 2, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 3,
2, 2, 1, 3, 3, 2, 2, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 1, 3, 2, 2, 2, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 3, 2, 2, 2, 2, 1, 2,
2, 3, 3, 3, 2, 3, 3, 3, 3, 2, 3, 3, 3, 3, 1, 3, 3, 3, 3, 2, 2, 2,
2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 3, 3, 2, 2, 3, 3, 3, 2, 1, 3, 3, 3,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 3, 3, 2, 2,
1, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
1, 2, 2, 2, 1, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 1])
Labels Generation¶
[8]:
Y, iAnn, Lam_r = MA_Clas_Gen(X ,t, R=5, NrP=1)
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:780: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:790: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(

[9]:
Y = Y - 1
t = t - 1
[10]:
from sklearn.metrics import classification_report
for i in range(Y.shape[1]):
print('annotator',i+1)
print(classification_report(t,Y[:,i]))
unique, counts = np.unique(Y[:,i], return_counts=True)
plt.figure()
plt.bar(unique, counts)
plt.title('Class Frequency for Y_true')
plt.xlabel('Class')
plt.ylabel('Frequency')
annotator 1
precision recall f1-score support
0 0.51 0.86 0.64 49
1 0.93 0.87 0.90 288
2 0.92 0.87 0.89 288
accuracy 0.87 625
macro avg 0.78 0.86 0.81 625
weighted avg 0.89 0.87 0.87 625
annotator 2
precision recall f1-score support
0 0.22 0.65 0.33 49
1 0.78 0.34 0.47 288
2 0.71 0.87 0.78 288
accuracy 0.61 625
macro avg 0.57 0.62 0.53 625
weighted avg 0.70 0.61 0.60 625
annotator 3
precision recall f1-score support
0 0.19 0.53 0.28 49
1 0.75 0.73 0.74 288
2 0.73 0.52 0.61 288
accuracy 0.62 625
macro avg 0.56 0.60 0.54 625
weighted avg 0.70 0.62 0.64 625
annotator 4
precision recall f1-score support
0 0.15 0.51 0.23 49
1 0.69 0.46 0.55 288
2 0.66 0.60 0.63 288
accuracy 0.53 625
macro avg 0.50 0.52 0.47 625
weighted avg 0.63 0.53 0.56 625
annotator 5
precision recall f1-score support
0 0.03 0.14 0.05 49
1 0.45 0.47 0.46 288
2 0.08 0.03 0.04 288
accuracy 0.24 625
macro avg 0.19 0.21 0.18 625
weighted avg 0.24 0.24 0.23 625
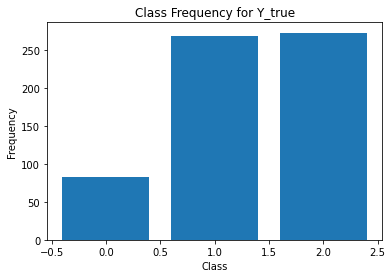
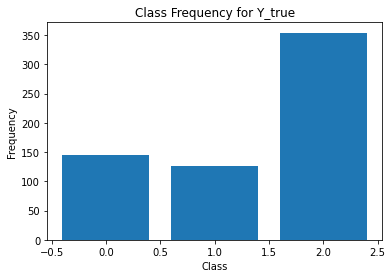
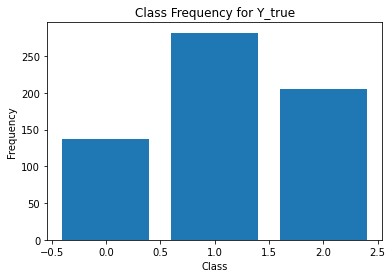
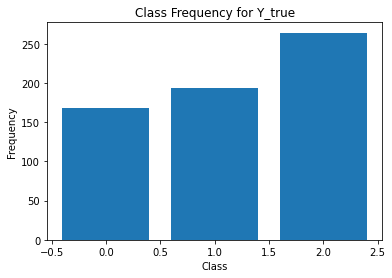

Split data¶
[11]:
import numpy.matlib
from sklearn.model_selection import ShuffleSplit, StratifiedShuffleSplit
Ns = 1
ss = ShuffleSplit(n_splits=Ns, test_size=0.3,random_state =123)
for train_index, test_index in ss.split(X):
print(test_index)
X_train, X_test,Y_train,Y_test = X[train_index,:], X[test_index,:],Y[train_index,:], Y[test_index,:]
Y_true_train, Y_true_test = t[train_index].reshape(-1,1), t[test_index].reshape(-1,1)
print(X_train.shape, Y_train.shape, Y_true_train.shape)
[618 454 423 593 338 404 345 132 150 379 54 386 508 378 242 43 602 11
237 192 520 48 333 543 209 524 82 102 374 142 177 288 171 298 348 131
384 246 470 566 138 353 421 491 320 604 474 85 367 477 527 567 57 548
356 272 164 264 263 481 430 200 437 5 166 35 509 205 156 542 202 120
243 107 9 620 601 78 560 134 422 574 282 59 328 512 31 199 185 568
172 285 396 587 482 611 151 155 297 391 66 275 501 406 502 252 274 266
75 582 383 327 13 600 300 227 310 431 397 162 79 529 335 221 294 614
349 622 488 231 270 514 350 36 446 381 196 577 416 550 34 33 212 588
347 118 15 230 159 429 398 93 217 181 556 190 403 116 336 456 452 170
426 457 368 280 30 0 72 408 277 392 344 234 362 74 511 24 549 273
64 402 268 226 261 575 55 287]
(437, 4) (437, 5) (437, 1)
Apply MinMaxScaler¶
[12]:
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Testing the Class¶
[24]:
from sklearn.metrics import classification_report, balanced_accuracy_score, roc_auc_score
from sklearn.metrics import normalized_mutual_info_score, mutual_info_score, adjusted_mutual_info_score
l1 =0.1
NUM_RUNS =10
ACC = np.zeros(NUM_RUNS)
AUC = np.zeros(NUM_RUNS)
AUCSK = np.zeros(NUM_RUNS)
MI = np.zeros(NUM_RUNS)
NMI = np.zeros(NUM_RUNS)
AMI = np.zeros(NUM_RUNS)
BACC = np.zeros(NUM_RUNS)
for i in range(NUM_RUNS): #10
print("iteration: " + str(i))
MA = Keras_MA_GCCE(epochs=100,batch_size=64,R=5, K=len(np.unique(Y_true_train)), dropout=0.2, learning_rate=0.01,optimizer='Adam',
l1_param=l1, validation_split=0, verbose=0, q=0.7, neurons=4)
MA.fit(X_train, Y_train)
MA.plot_history()
#Accuracy
pred_2 = MA.predict(X_test)
report = classification_report( pred_2[:,Y.shape[1]:].argmax(axis=1),Y_true_test.ravel(),output_dict=True)
ACC[i] = report['accuracy']
print("Validation ACC: %.4f" % (float(ACC[i])))
# balanced. Accurcy
BACC[i] = balanced_accuracy_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze(), adjusted=True)
print("Validation Balanced_ACC: %.4f" % (float(BACC[i])))
#MI
MI[i] = mutual_info_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze())
print("Validation MI: %.4f" % (float(MI[i]),))
NMI[i] = normalized_mutual_info_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze())
print("Validation Normalized MI: %.4f" % (float(NMI[i]),))
AMI[i]= adjusted_mutual_info_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze())
print("Validation Adjusted MI: %.4f" % (float(AMI[i]),))
#AUC
val_AUC_metric = tf.keras.metrics.AUC( from_logits = True)
# val_logits =MA.predict(X_test) # model(X_test, training=False)
# tf.print(y_batch_val)
val_AUC_metric.update_state(Y_true_test, pred_2[:,Y.shape[1]:].argmax(axis=1).astype('float'))
val_AUC = val_AUC_metric.result()
val_AUC_metric.reset_states()
val_AUC = val_AUC.numpy()
print("Validation aUc: %.4f" % (float(val_AUC),))
AUC[i] = val_AUC
val_AUC1 = roc_auc_score(ook(Y_true_test), pred_2[:,Y_train.shape[1]:])
print("Validation aUc_Sklearn: %.4f" % (float(val_AUC1),))
AUCSK[i] = val_AUC1
iteration: 0

6/6 [==============================] - 0s 3ms/step
Validation ACC: 0.8777
Validation Balanced_ACC: 0.4558
Validation MI: 0.4856
Validation Normalized MI: 0.6046
Validation Adjusted MI: 0.6019
Validation aUc: 0.6152
Validation aUc_Sklearn: 0.9583
iteration: 1
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8777
Validation Balanced_ACC: 0.4565
Validation MI: 0.5003
Validation Normalized MI: 0.6232
Validation Adjusted MI: 0.6207
Validation aUc: 0.6094
Validation aUc_Sklearn: 0.9539
iteration: 2
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))

6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8777
Validation Balanced_ACC: 0.4558
Validation MI: 0.4776
Validation Normalized MI: 0.5943
Validation Adjusted MI: 0.5915
Validation aUc: 0.5152
Validation aUc_Sklearn: 0.9654
iteration: 3
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8777
Validation Balanced_ACC: 0.4558
Validation MI: 0.4818
Validation Normalized MI: 0.5995
Validation Adjusted MI: 0.5968
Validation aUc: 0.4152
Validation aUc_Sklearn: 0.9652
iteration: 4
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))

6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8670
Validation Balanced_ACC: 0.4457
Validation MI: 0.4879
Validation Normalized MI: 0.6092
Validation Adjusted MI: 0.6066
Validation aUc: 0.6703
Validation aUc_Sklearn: 0.9579
iteration: 5
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))

6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8936
Validation Balanced_ACC: 0.4728
Validation MI: 0.5385
Validation Normalized MI: 0.6703
Validation Adjusted MI: 0.6680
Validation aUc: 0.4181
Validation aUc_Sklearn: 0.9625
iteration: 6
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))

6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.9043
Validation Balanced_ACC: 0.4837
Validation MI: 0.5720
Validation Normalized MI: 0.7118
Validation Adjusted MI: 0.7098
Validation aUc: 0.5906
Validation aUc_Sklearn: 0.9653
iteration: 7
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
6/6 [==============================] - 0s 3ms/step
Validation ACC: 0.8777
Validation Balanced_ACC: 0.4558
Validation MI: 0.4777
Validation Normalized MI: 0.5943
Validation Adjusted MI: 0.5916
Validation aUc: 0.4819
Validation aUc_Sklearn: 0.9577
iteration: 8
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8777
Validation Balanced_ACC: 0.4565
Validation MI: 0.4929
Validation Normalized MI: 0.6135
Validation Adjusted MI: 0.6109
Validation aUc: 0.5094
Validation aUc_Sklearn: 0.9526
iteration: 9
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
6/6 [==============================] - 0s 2ms/step
Validation ACC: 0.8830
Validation Balanced_ACC: 0.4620
Validation MI: 0.5072
Validation Normalized MI: 0.6314
Validation Adjusted MI: 0.6288
Validation aUc: 0.5457
Validation aUc_Sklearn: 0.9621
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
[15]:
ACC
[15]:
array([0.85638298, 0.88297872, 0.90425532, 0.88297872, 0.88829787,
0.86702128, 0.88829787, 0.88297872, 0.87765957, 0.88829787])
[16]:
AUC
[16]:
array([0.73121387, 0.58477837, 0.52967244, 0.57899803, 0.5152216 ,
0.5094412 , 0.64855498, 0.57899803, 0.5152216 , 0.64855498])
[17]:
print('Average Accuracy: ', np.round( ACC.mean(),4)*100)
print('Average std: ',np.round(np.std( ACC),4)*100)
Average Accuracy: 88.19
Average std: 1.23
[18]:
print('Average Balanced Accuracy: ', np.round( BACC.mean(),4)*100)
print('Average std: ',np.round(np.std( BACC),4)*100)
Average Balanced Accuracy: 46.06
Average std: 1.26
[19]:
print('Average AUC: ', np.round( AUC.mean(),4)*100)
print('Average AUC std: ',np.round(np.std( AUC),4)*100)
Average AUC: 58.41
Average AUC std: 6.93
[20]:
print('Average MI: ', np.round( MI.mean(),4)*100)
print('Average std: ',np.round(np.std(MI),4)*100)
Average MI: 50.82
Average std: 2.8899999999999997
[21]:
print('Average Normalized MI: ', np.round( NMI.mean(),4)*100)
print('Average std: ',np.round(np.std(NMI),4)*100)
Average Normalized MI: 63.3
Average std: 3.5900000000000003
[22]:
print('Average Ajdusted MI: ', np.round( AMI.mean(),4)*100)
print('Average std: ',np.round(np.std(AMI),4)*100)
Average Ajdusted MI: 63.05
Average std: 3.61
[25]:
print('Average Accuracy: ', np.round( ACC.mean(),4)*100)
print('Average std: ',np.round(np.std( ACC),4)*100)
print('==============================================')
print('Average AUC: ', np.round( AUC.mean(),4)*100)
print('Average AUC std: ',np.round(np.std( AUC),4)*100)
print('==============================================')
print('Average AUC Sklearn: ', np.round( AUCSK.mean(),4)*100)
print('Average AUC SK std: ',np.round(np.std( AUCSK),4)*100)
print('==============================================')
print('Average Balanced Accuracy: ', np.round( BACC.mean(),4)*100)
print('Average std: ',np.round(np.std( BACC),4)*100)
print('==============================================')
print('Average MI: ', np.round( MI.mean(),4)*100)
print('Average std: ',np.round(np.std(MI),4)*100)
print('==============================================')
print('Average Normalized MI: ', np.round( NMI.mean(),4)*100)
print('Average std: ',np.round(np.std(NMI),4)*100)
print('==============================================')
print('Average Ajdusted MI: ', np.round( AMI.mean(),4)*100)
print('Average std: ',np.round(np.std(AMI),4)*100)
Average Accuracy: 88.14
Average std: 0.98
==============================================
Average AUC: 53.71
Average AUC std: 8.08
==============================================
Average AUC Sklearn: 96.00999999999999
Average AUC SK std: 0.44999999999999996
==============================================
Average Balanced Accuracy: 46.0
Average std: 1.02
==============================================
Average MI: 50.22
Average std: 2.9000000000000004
==============================================
Average Normalized MI: 62.519999999999996
Average std: 3.5999999999999996
==============================================
Average Ajdusted MI: 62.27
Average std: 3.62
[26]:
import pickle
# create the dictionary with 6 scalar variables
Metrics = {
'Accuracy': np.round( ACC.mean(),4)*100,
'Accuracy_std': np.round(np.std( ACC),4)*100,
'AUC': np.round( AUC.mean(),4)*100,
'AUC_std': np.round(np.std( AUC),4)*100,
'Balanced Accuracy': np.round( BACC.mean(),4)*100,
'Balanced Accuracy_std': np.round(np.std(BACC),4)*100,
'MI': np.round( MI.mean(),4)*100,
'MI_std': np.round(np.std(MI),4)*100,
'Normalized MI': np.round( NMI.mean(),4)*100,
'Normalized MI_std': np.round(np.std(NMI),4)*100,
'Adjusted MI': np.round( AMI.mean(),4)*100,
'Adjusted MI_std': np.round(np.std(NMI),4)*100,
}
# save the dictionary to a file using pickle
with open('data.pickle', 'wb') as handle:
pickle.dump(Metrics, handle, protocol=pickle.HIGHEST_PROTOCOL)