Imports¶
[1]:
import tensorflow_datasets as tfds
import tensorflow as tf
import keras
from keras.models import Sequential,Model
from keras.layers import Dense,Conv2D,Flatten,MaxPooling2D,GlobalAveragePooling2D
from keras.utils.vis_utils import plot_model
from tensorflow.keras import regularizers
import numpy as np
import matplotlib.pyplot as plt
import scipy as sp
import cv2
import os
import time
import sys
import tensorflow_datasets as tfds
import tensorflow as tf
import keras
from keras.models import Sequential,Model
from keras.layers import Dense,Conv2D,Flatten,MaxPooling2D,GlobalAveragePooling2D
from keras.utils.vis_utils import plot_model
import pandas as pd
import pickle
[2]:
from sklearn.metrics import classification_report, accuracy_score, balanced_accuracy_score, roc_auc_score, mutual_info_score, normalized_mutual_info_score, adjusted_mutual_info_score
import tensorflow as tf
import numpy as np
from scipy.io import loadmat
from sklearn.preprocessing import StandardScaler
from scipy.io import savemat
from sklearn.metrics import roc_auc_score
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.decomposition import PCA
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
def scheduler1(step = 10, ratio = 1.2):
def scheduler(epoch, lr):
if epoch % step == 0 and epoch>1:
return lr/ratio
else:
return lr
return scheduler
def evaluation_metrics(y_true, y_pred, print_result=True):
acc = 0
auc = 0
auc_sk = 0
#mi = 0
nmi = 0
#ami = 0
bacc = 0
# Accuracy
#report = classification_report(y_pred.argmax(axis=1), y_true.ravel(), output_dict=True)
acc = accuracy_score( y_true.ravel(), y_pred.argmax(axis=1)) #report['accuracy']
# Balanced accuracy
bacc = balanced_accuracy_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze(), adjusted=True)
# # Mutual Information
# mi = mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Normalized Mutual Information
nmi = normalized_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Adjusted Mutual Information
#ami = adjusted_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# AUC (Tensorflow)
auc_metric = tf.keras.metrics.AUC(from_logits=True)
auc_metric.update_state(y_true, y_pred.argmax(axis=1).astype('float'))
auc = auc_metric.result().numpy()
auc_metric.reset_states()
# AUC (scikit-learn)
auc_sk = roc_auc_score(ook(y_true), y_pred)
if print_result:
print("Accuracy: {:.4f}".format(acc))
print("Balanced Accuracy: {:.4f}".format(bacc))
print("Mutual Information: {:.4f}".format(mi))
print("Normalized Mutual Information: {:.4f}".format(nmi))
print("Adjusted Mutual Information: {:.4f}".format(ami))
print("AUC (Tensorflow): {:.4f}".format(auc))
print("AUC (scikit-learn): {:.4f}".format(auc_sk))
return acc, auc, auc_sk, nmi, bacc # mi, , ami
Multiple annotators model¶
[3]:
#cargar datos desde drive acceso libre
FILEID = "1zIcnmybob9XUBExCXzhCvqKkVgg4Qw5L"
#https://drive.google.com/file/d/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O Cifar-10H.zip && rm -rf /tmp/cookies.txt
!unzip -o Cifar-10H.zip
!dir
--2023-02-15 06:37:11-- https://docs.google.com/uc?export=download&confirm=t&id=1zIcnmybob9XUBExCXzhCvqKkVgg4Qw5L
Resolving docs.google.com (docs.google.com)... 142.251.107.101, 142.251.107.138, 142.251.107.113, ...
Connecting to docs.google.com (docs.google.com)|142.251.107.101|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-08-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ls1h8g8q7j79ni6vg8kk2o8nvedpkq8t/1676442975000/07591141114418430227/*/1zIcnmybob9XUBExCXzhCvqKkVgg4Qw5L?e=download&uuid=6addc5d4-253f-4b86-bfd8-c387eeec9fd4 [following]
Warning: wildcards not supported in HTTP.
--2023-02-15 06:37:11-- https://doc-08-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ls1h8g8q7j79ni6vg8kk2o8nvedpkq8t/1676442975000/07591141114418430227/*/1zIcnmybob9XUBExCXzhCvqKkVgg4Qw5L?e=download&uuid=6addc5d4-253f-4b86-bfd8-c387eeec9fd4
Resolving doc-08-90-docs.googleusercontent.com (doc-08-90-docs.googleusercontent.com)... 74.125.31.132, 2607:f8b0:400c:c02::84
Connecting to doc-08-90-docs.googleusercontent.com (doc-08-90-docs.googleusercontent.com)|74.125.31.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 68469211 (65M) [application/zip]
Saving to: ‘Cifar-10H.zip’
Cifar-10H.zip 100%[===================>] 65.30M 71.0MB/s in 0.9s
2023-02-15 06:37:12 (71.0 MB/s) - ‘Cifar-10H.zip’ saved [68469211/68469211]
Archive: Cifar-10H.zip
inflating: Cifar-10H/DataProcessing.ipynb
inflating: Cifar-10H/batches.meta
inflating: Cifar-10H/Answers_Processed.csv
inflating: Cifar-10H/data_batch_1
inflating: Cifar-10H/cifar10h-raw.csv
inflating: Cifar-10H/test_batch
Cifar-10H Cifar-10H.zip __notebook__.ipynb
[4]:
Data_dir = '/kaggle/working/Cifar-10H/test_batch'
labels_dir = '/kaggle/working/Cifar-10H/Answers_Processed.csv'
[5]:
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
[6]:
def arr_to_im(X):
N = X.shape[0]
X_tr = np.zeros((N,32,32,3))
for i,x in enumerate(X):
aux = x.reshape(3,32,32)/255
aux = aux.transpose(1,2,0)
X_tr[i,:] = cv2.resize(aux, (32,32))
return X_tr
[7]:
X = unpickle(Data_dir)[b'data']
Label = pd.read_csv(labels_dir, header=None)
Label = Label.to_numpy()
Y = Label[:,:-1]
y = Label[:,-1][:,np.newaxis]
N, R = Y.shape
K = len(np.unique(y))
# y = Label[:,np.newaxis]
[8]:
# Se eliminan las muestras que no fueron etiquetadas por ningun anotador
idx_ = np.sum(Y,axis=1) != R*(-999)
X = X[idx_,:]
Y = Y[idx_,:]
N, R = Y.shape
y = y[idx_,:]
X = arr_to_im(X)
Test data¶
[9]:
Test_dir = '/kaggle/working/Cifar-10H/data_batch_1'
[10]:
X_te = unpickle(Test_dir)[b'data']
X_te = arr_to_im(X_te)
y_te = np.array(unpickle(Test_dir)[b'labels'])[:,np.newaxis]
[11]:
train_batchesMA = tf.data.Dataset.from_tensor_slices((X,y, Y))
train_batchesMA = train_batchesMA.shuffle(1024).batch(64)
2023-02-15 06:37:17.325900: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:17.493430: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:17.494293: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:17.497116: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-02-15 06:37:17.497462: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:17.498197: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:17.498853: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:19.744215: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:19.745127: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:19.745860: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2023-02-15 06:37:19.746460: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 15401 MB memory: -> device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0
[12]:
# -*- coding: utf-8 -*-
import tensorflow as tf
import matplotlib.pyplot as plt
#from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
import tensorflow_probability as tfp
from tensorflow.keras import regularizers
from sklearn.base import BaseEstimator, TransformerMixin, ClassifierMixin
from sklearn.model_selection import train_test_split
tf.keras.backend.clear_session()
#tf.random.set_seed(42)
import types
import tempfile
class Keras_MA_RCDNN(): #transformer no va
#Constructor __init__. Special method: identified by a double underscore at either side of their name
#work in the background
# initialize data members to the object. lets the class initialize the object’s attributes and serves no other purpose.
def __init__(self,epochs=100,batch_size=30,R=5, K=2, dropout=0.5, learning_rate=1e-3,optimizer='Adam',
l1_param=0, validation_split=0.3, verbose=1, q = 0.1):
self.epochs=epochs
self.dropout=dropout
self.batch_size = batch_size
self.learning_rate=learning_rate
self.l1_param=l1_param
self.l2_param=l1_param
self.validation_split = validation_split
self.verbose = verbose
self.optimizer = optimizer
self.R=R
self.K=K
self.q = q
def custom_RCDNN_loss(self, y_true, y_pred): #ytrue \in N x R, ypred \in N x (R+K) -> PRI->JULI
#Input ytrue: samples (N) x annotators (R)
#Input ypred: samples (N) x annotators+classes (R+K)
#Ground truth estimation samples (N) x Classes(K)
pred = y_pred[:,self.R:]
pred = tf.clip_by_value(pred, clip_value_min=1e-9, clip_value_max=1-1e-9) #estabilidad numerica de la funcion de costo
# Annotators reliability prediction: samples (N) x annotators (R)
ann_ = y_pred[:,:self.R]
#Y_true 1-K: samples (N) x Classes(1-K), annotators (R)
Y_true = tf.one_hot(tf.cast(y_true, dtype=tf.int32), depth=self.K, axis=1)
#Y_pred 1 - K: samples (N) x Classes(1-K), annotators (R)
Y_hat = tf.repeat(tf.expand_dims(pred,-1), self.R, axis = -1)
#loss computation
p_logreg = tf.math.reduce_prod(tf.math.pow(Y_hat, Y_true), axis=1)
temp1 = ann_*tf.math.log(p_logreg)
temp2 = (1 - ann_)*tf.math.log(1/self.K)*tf.reduce_sum(Y_true,axis=1)
# temp2 = (tf.ones(tf.shape(ann_)) - ann_)*tf.math.log(1/K)
# print(tf.reduce_mean(Y_true,axis=1).numpy())
return -tf.math.reduce_sum((temp1 + temp2))
def GCCE_MA_loss(self, y_true, y_pred):
# print(y_true,y_pred)
# q = 0.1
pred = y_pred[:, self.R:]
pred = tf.clip_by_value(pred, clip_value_min=1e-9, clip_value_max=1)
ann_ = y_pred[:, :self.R]
# ann_ = tf.clip_by_value(ann_, clip_value_min=1e-9, clip_value_max=1-1e-9)
Y_true = tf.one_hot(tf.cast(y_true, dtype=tf.int32), depth=self.K, axis=1)
Y_hat = tf.repeat(tf.expand_dims(pred,-1), self.R, axis = -1)
p_gcce = Y_true*(1 - Y_hat**self.q)/self.q
temp1 = ann_*tf.math.reduce_sum(p_gcce, axis=1)
# p_logreg = tf.math.reduce_prod(tf.math.pow(Y_hat, Y_true), axis=1)
# temp1 = ann_*tf.math.log(p_logreg)
# temp2 = (1 - ann_)*tf.math.log(1/K)*tf.reduce_sum(Y_true,axis=1)
# aux = tf.repeat(tf.reduce_sum(pred*tf.math.log(pred),axis=1,keepdims=True), R, axis = 1)
# tf.print(tf.shape(aux))
# print(tf.shape(aux))
# temp2 = (1 - ann_)*aux*tf.reduce_sum(Y_true,axis=1)
# temp2 = (tf.ones(tf.shape(ann_)) - ann_)*tf.math.log(1/K)
# print(tf.reduce_mean(Y_true,axis=1).numpy())
# Y_true_1 = tf.clip_by_value(Y_true, clip_value_min=1e-9, clip_value_max=1)
# p_logreg_inv = tf.math.reduce_prod(tf.math.pow(Y_true_1, Y_hat), axis=1)
# temp2 = (1 - ann_)*tf.math.log(p_logreg_inv)
temp2 = (1 - ann_)*(1-(1/self.K)**self.q)/self.q*tf.reduce_sum(Y_true,axis=1)
return tf.math.reduce_sum((temp1 + temp2))
def PRI_MA_loss(self, y_true, y_pred): #, -> PRI
#Input ytrue: samples (N) x annotators (R)
#Input ypred: samples (N) x annotators+classes (R+K)
#PRI MA
cce_M = tf.keras.losses.CategoricalCrossentropy(reduction='none',axis=-1)
cce_C = tf.keras.losses.CategoricalCrossentropy(reduction='none',axis=1)
#N = tf.cast(y_true.shape[0],dtype=tf.int32)
N = tf.shape(y_true)[0]
#Ground truth estimation samples (N) x Classes(K)
y_pred_tf = y_pred[:,self.R:]
# Annotators reliability prediction: samples (N) x annotators (R)
lambda_R_tf = y_pred[:,:self.R] #tf.ones(shape=(N,R))
#Y_true 1 K: samples (N) x Classes(1-K), annotators (R)
Y_true_1K = tf.one_hot(tf.cast(y_true,dtype=tf.int32),depth=self.K,axis=1)
#Y_pred 1 - K: samples (N) x Classes(1-K), annotators (R)
Y_hat = tf.repeat(tf.expand_dims(y_pred_tf,-1), self.R, axis = -1)
#marginal entropy
#cce along the K classes -> ypred_tf
Hm_ = cce_M(y_pred_tf,y_pred_tf)
#cross entropy
#cce along the K classes -> Y_hat
Hc_ = cce_C(Y_true_1K,Y_hat)
#PRI MA computation
LH = tf.linalg.matmul(lambda_R_tf,Hc_,transpose_a=True) # \Lambda^\top H_c
temp1 = tf.linalg.trace(LH) #trace(LH)
Hm1L = tf.linalg.matmul(tf.ones(shape=(N,self.R))-lambda_R_tf,tf.ones(shape=(self.R,1)))# 1_N 1_R^\top - Lambda
Hm_t = tf.reshape(Hm_,shape=(N,1))
temp2 = tf.squeeze(tf.linalg.matmul(Hm_t,Hm1L,transpose_a=True)) # Hm^\top Hm1L
loss_c = temp1+ temp2 #return loss
return loss_c
def fit(self, X, Y):
#input X numpy array first dimension samples (N)x features (P)
#input Y numpy array vector len = samples (N) x annotators (R)
P = X.shape[1]
if self.optimizer == "Adam":
opt = tf.keras.optimizers.Adam(learning_rate=self.learning_rate, clipnorm=1.0)
elif self.optimizer == "SGD":
opt = tf.keras.optimizers.SGD(learning_rate=self.learning_rate, clipnorm=1.0)
else:
opt=self.optimizer
num_filters2 =32
# Block 1
input_l = tf.keras.layers.Input(shape=(32, 32, 3), name='entrada')
x = keras.layers.Conv2D(num_filters2, (3, 3), activation="relu" , kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param, l2= self.l1_param),
name="block1_conv1")(input_l)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(num_filters2, (3, 3), activation="relu" , kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param, l2= self.l1_param),
name="block1_conv2")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.MaxPooling2D((2, 2), name="block1_pool")(x)
x = keras.layers.Dropout(self.dropout)(x)
# x = tf.keras.layers.Conv2D(32, (3, 3), activation="relu" , name="block1_conv1")(input_l)
# x = tf.keras.layers.BatchNormalization()(x)
# x = tf.keras.layers.MaxPooling2D((2, 2), strides=(2, 2), name="block1_pool")(x)
# Block 2
#x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(num_filters2*2, (3, 3), activation="relu",
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param, l2= self.l1_param), name="block2_conv1")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(num_filters2*2, (3, 3), activation="relu",
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param, l2= self.l1_param), name="block2_conv2")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.MaxPooling2D((2, 2), name="block2_pool")(x)
x = keras.layers.Dropout(self.dropout)(x)
# Block 3
#x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(num_filters2*4, (3, 3), activation="relu",
kernel_regularizer= tf.keras.regularizers.l1_l2(l1=self.l1_param, l2= self.l1_param), name="block3_conv1")(x)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Conv2D(num_filters2*4, (3, 3), activation="relu",
kernel_regularizer= tf.keras.regularizers.l1_l2(l1=self.l1_param, l2= self.l1_param), name="block3_conv2")(x)
x = keras.layers.BatchNormalization()(x)
#x = keras.layers.MaxPooling2D((2, 2), name="block2_pool")(x)
x = keras.layers.Dropout(self.dropout)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dense(512,activation="relu")(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(self.dropout)(x)
output_R = tf.keras.layers.Dense(self.R,activation="sigmoid",
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param,l2=self.l2_param), name= 'out_R_GCCE' )(x)
output_K = tf.keras.layers.Dense(self.K,activation="softmax",
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param,l2=self.l2_param), name= 'out_K_GCCE')(x)
output = tf.keras.layers.concatenate([output_R, output_K])
self.model = tf.keras.Model(inputs= input_l,outputs=output)
self.model.compile(loss=self.GCCE_MA_loss, optimizer=opt)
self.history = self.model.fit(X, Y, epochs=self.epochs, validation_split=self.validation_split, #
batch_size=self.batch_size,verbose=self.verbose)
return self
def predict(self, X, *_):
#input X numpy array first dimension samples (N)x features (P)
return self.model.predict(X)
def fit_predict(self,X,y):
#input X numpy array first dimension samples (N)x features (P)
#input Y numpy array vector len = samples (N) x annotators (R)
self.fit(X,y)
return self.predict(X)
#graphics
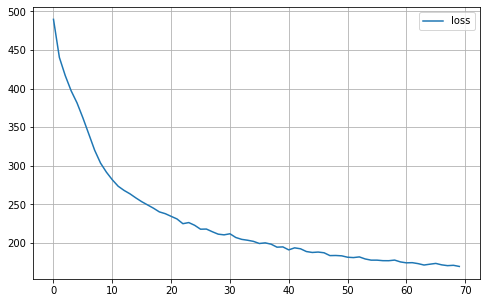
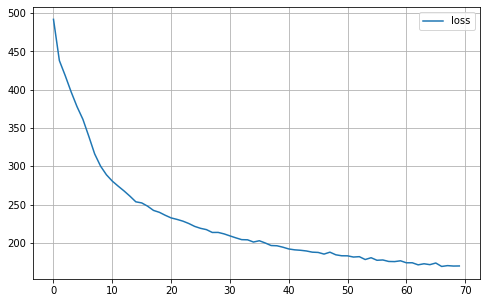
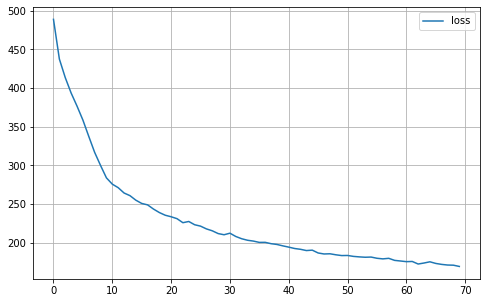
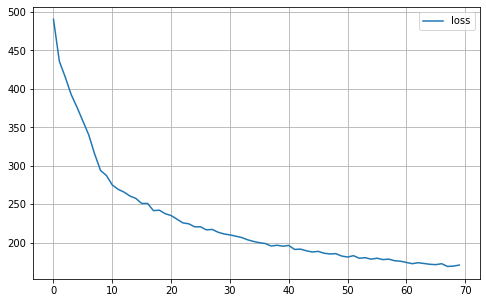
def plot_history(self):
pd.DataFrame(self.history.history).plot(figsize=(8, 5))
plt.grid(True)
#plt.gca().set_ylim(0, 1)
#save_fig("keras_learning_curves_plot")
plt.show()
return
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def get_params(self, deep=True):
return { 'l1_param':self.l1_param, 'dropout':self.dropout, 'optimizer':self.optimizer,
'learning_rate':self.learning_rate, 'batch_size':self.batch_size,
'epochs':self.epochs, 'verbose':self.verbose, 'validation_split':self.validation_split,
'R':self.R, 'K':self.K, 'q':self.q
}
return self
[13]:
train_batches = tf.data.Dataset.from_tensor_slices((X,y))
test_batches = tf.data.Dataset.from_tensor_slices((X_te,y_te))
Build the classifier from multiple annotators¶
[14]:
import tensorflow as tf
import numpy as np
from scipy.io import loadmat
from sklearn.preprocessing import StandardScaler
from scipy.io import savemat
from sklearn.metrics import roc_auc_score
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.decomposition import PCA
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
def scheduler1(step = 10, ratio = 1.2):
def scheduler(epoch, lr):
if epoch % step == 0 and epoch>1:
return lr/ratio
else:
return lr
return scheduler
[15]:
from sklearn.metrics import classification_report, balanced_accuracy_score
from sklearn.metrics import normalized_mutual_info_score, mutual_info_score, adjusted_mutual_info_score
l1 =0.0001
NUM_RUNS =10
results = []
for i in range(NUM_RUNS):
print("iteration: " + str(i))
MA = Keras_MA_RCDNN(epochs=70,batch_size=64,R=Y.shape[1], K=len(np.unique(y)), dropout=0.5, learning_rate=0.001,optimizer='Adam',
l1_param=l1, validation_split=0, verbose=0, q=0.01)
MA.fit(X , Y )
MA.plot_history()
#MA.plot_history()
# Generate the predictions for the current run
pred_2 = MA.predict(X_te)
Y_true_test = y_te
acc, auc, auc_sk, nmi, bacc = evaluation_metrics(Y_true_test, pred_2[:,Y.shape[1]:], print_result=False) # mi, ami,
# Save the results for the current run to the list of dictionaries
results.append({
#'run': i,
'accuracy': acc,
'balanced_accuracy': bacc,
# 'mutual_information': mi,
'normalized_mutual_information': nmi,
# 'adjusted_mutual_information': ami,
'auc_tensorflow': auc,
'auc_scikit_learn': auc_sk,
})
# Convert the list of dictionaries to a DataFrame
df = np.round(pd.DataFrame(results)*100, 2)
# Calculate the mean and standard deviation of each metric
mean = np.round(df.mean(),2)
std = np.round(df.std(),2)
iteration: 0
2023-02-15 06:37:23.641121: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
2023-02-15 06:37:27.228257: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8005
iteration: 1

iteration: 2
iteration: 3
iteration: 4
iteration: 5
iteration: 6

iteration: 7
iteration: 8
iteration: 9
[16]:
df
[16]:
| accuracy | balanced_accuracy | normalized_mutual_information | auc_tensorflow | auc_scikit_learn | |
|---|---|---|---|---|---|
| 0 | 67.82 | 64.30 | 49.37 | 81.730003 | 94.72 |
| 1 | 70.05 | 66.82 | 51.45 | 82.040001 | 95.24 |
| 2 | 69.45 | 66.10 | 51.50 | 82.690002 | 95.06 |
| 3 | 69.72 | 66.47 | 51.84 | 80.639999 | 95.28 |
| 4 | 69.52 | 66.20 | 50.86 | 86.510002 | 94.93 |
| 5 | 69.62 | 66.31 | 50.87 | 83.709999 | 95.14 |
| 6 | 69.34 | 65.94 | 51.14 | 82.720001 | 95.02 |
| 7 | 69.15 | 65.85 | 50.98 | 82.750000 | 94.90 |
| 8 | 69.40 | 65.94 | 51.59 | 82.019997 | 95.11 |
| 9 | 68.32 | 64.85 | 49.88 | 81.980003 | 94.73 |
[17]:
mean
[17]:
accuracy 69.24
balanced_accuracy 65.88
normalized_mutual_information 50.95
auc_tensorflow 82.68
auc_scikit_learn 95.01
dtype: float64
[18]:
std
[18]:
accuracy 0.67
balanced_accuracy 0.76
normalized_mutual_information 0.78
auc_tensorflow 1.57
auc_scikit_learn 0.19
dtype: float64
[19]:
result_df = pd.concat([mean.rename('Mean'), std.rename('Std')], axis=1)
result_df
[19]:
| Mean | Std | |
|---|---|---|
| accuracy | 69.24 | 0.67 |
| balanced_accuracy | 65.88 | 0.76 |
| normalized_mutual_information | 50.95 | 0.78 |
| auc_tensorflow | 82.68 | 1.57 |
| auc_scikit_learn | 95.01 | 0.19 |
[20]:
# # Save the DataFrame to an excel file
# result_df.to_excel(database + custom_loss + ".xlsx")