![]()
[26]:
import tensorflow as tf
from sklearn.metrics import classification_report, accuracy_score, balanced_accuracy_score, roc_auc_score, mutual_info_score, normalized_mutual_info_score, adjusted_mutual_info_score
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import numpy as np
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
def evaluation_metrics(y_true, y_pred, print_result=True):
acc = 0
auc = 0
auc_sk = 0
#mi = 0
nmi = 0
#ami = 0
bacc = 0
# Accuracy
#report = classification_report(y_pred.argmax(axis=1), y_true.ravel(), output_dict=True)
acc = accuracy_score( y_true.ravel(), y_pred.argmax(axis=1)) #report['accuracy']
# Balanced accuracy
bacc = balanced_accuracy_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze(), adjusted=True)
# # Mutual Information
# mi = mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Normalized Mutual Information
nmi = normalized_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Adjusted Mutual Information
#ami = adjusted_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# AUC (Tensorflow)
auc_metric = tf.keras.metrics.AUC(from_logits=True)
auc_metric.update_state(y_true, y_pred.argmax(axis=1).astype('float'))
auc = auc_metric.result().numpy()
auc_metric.reset_states()
# AUC (scikit-learn)
auc_sk = roc_auc_score(ook(y_true), y_pred)
if print_result:
print("Accuracy: {:.4f}".format(acc))
print("Balanced Accuracy: {:.4f}".format(bacc))
print("Mutual Information: {:.4f}".format(mi))
print("Normalized Mutual Information: {:.4f}".format(nmi))
print("Adjusted Mutual Information: {:.4f}".format(ami))
print("AUC (Tensorflow): {:.4f}".format(auc))
print("AUC (scikit-learn): {:.4f}".format(auc_sk))
return acc, auc, auc_sk, nmi, bacc # mi, , ami
Subclassing for RCDNN¶
[27]:
!git clone https://github.com/Jectrianama/GCCE_TEST.git
fatal: destination path 'GCCE_TEST' already exists and is not an empty directory.
[28]:
import os
os.chdir('/content/GCCE_TEST/Models')
#from keras_ma_gcce import *
from labels_generation import MA_Clas_Gen
os.chdir('../../')
[29]:
#cargar datos desde drive otros dataset
FILEID = "1AU8pTtCLihBjCZjWITaAzpnEuL4RO436"
#https://drive.google.com/file/d/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O DataGCCE.zip && rm -rf /tmp/cookies.txt
!unzip -o DataGCCE.zip
!dir
--2023-02-13 18:02:29-- https://docs.google.com/uc?export=download&confirm=&id=1AU8pTtCLihBjCZjWITaAzpnEuL4RO436
Resolving docs.google.com (docs.google.com)... 142.250.31.138, 142.250.31.101, 142.250.31.139, ...
Connecting to docs.google.com (docs.google.com)|142.250.31.138|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/4mt4p83toi1h4bbj8vlhp2kk640g74o2/1676311350000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=e8cca8b8-d89a-4c92-bbed-8ed4752549a9 [following]
Warning: wildcards not supported in HTTP.
--2023-02-13 18:02:30-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/4mt4p83toi1h4bbj8vlhp2kk640g74o2/1676311350000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=e8cca8b8-d89a-4c92-bbed-8ed4752549a9
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 142.251.163.132, 2607:f8b0:4004:c1b::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|142.251.163.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 38377 (37K) [application/x-zip-compressed]
Saving to: ‘DataGCCE.zip’
DataGCCE.zip 100%[===================>] 37.48K --.-KB/s in 0.001s
2023-02-13 18:02:30 (55.8 MB/s) - ‘DataGCCE.zip’ saved [38377/38377]
Archive: DataGCCE.zip
inflating: new-thyroid.csv
inflating: tic-tac-toe-endgame.csv
inflating: balance-scale.csv
inflating: file.csv
balance-scale.csv GCCE_TEST new-thyroid.csv TicTacToeGCE.xlsx
DataGCCE.zip MADatasets sample_data
file.csv MADatasets.zip tic-tac-toe-endgame.csv
[30]:
# -*- coding: utf-8 -*-
import tensorflow as tf
import matplotlib.pyplot as plt
#from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
import tensorflow_probability as tfp
from tensorflow.keras import regularizers
from sklearn.base import BaseEstimator, TransformerMixin, ClassifierMixin
from sklearn.model_selection import train_test_split
tf.keras.backend.clear_session()
#tf.random.set_seed(42)
import types
import tempfile
class Keras_MA_RCDNN(): #transformer no va
#Constructor __init__. Special method: identified by a double underscore at either side of their name
#work in the background
# initialize data members to the object. lets the class initialize the object’s attributes and serves no other purpose.
def __init__(self,epochs=100,batch_size=30,R=5, K=2, dropout=0.5, learning_rate=1e-3,optimizer='Adam',
l1_param=0, validation_split=0.3, verbose=1, q = 0.1):
self.epochs=epochs
self.dropout=dropout
self.batch_size = batch_size
self.learning_rate=learning_rate
self.l1_param=l1_param
self.l2_param=l1_param
self.validation_split = validation_split
self.verbose = verbose
self.optimizer = optimizer
self.R=R
self.K=K
self.q = q
def custom_RCDNN_loss(self, y_true, y_pred): #ytrue \in N x R, ypred \in N x (R+K) -> PRI->JULI
#Input ytrue: samples (N) x annotators (R)
#Input ypred: samples (N) x annotators+classes (R+K)
#Ground truth estimation samples (N) x Classes(K)
pred = y_pred[:,self.R:]
pred = tf.clip_by_value(pred, clip_value_min=1e-9, clip_value_max=1-1e-9) #estabilidad numerica de la funcion de costo
# Annotators reliability prediction: samples (N) x annotators (R)
ann_ = y_pred[:,:self.R]
#Y_true 1-K: samples (N) x Classes(1-K), annotators (R)
Y_true = tf.one_hot(tf.cast(y_true, dtype=tf.int32), depth=self.K, axis=1)
#Y_pred 1 - K: samples (N) x Classes(1-K), annotators (R)
Y_hat = tf.repeat(tf.expand_dims(pred,-1), self.R, axis = -1)
#loss computation
p_logreg = tf.math.reduce_prod(tf.math.pow(Y_hat, Y_true), axis=1)
temp1 = ann_*tf.math.log(p_logreg)
temp2 = (1 - ann_)*tf.math.log(1/self.K)*tf.reduce_sum(Y_true,axis=1)
# temp2 = (tf.ones(tf.shape(ann_)) - ann_)*tf.math.log(1/K)
# print(tf.reduce_mean(Y_true,axis=1).numpy())
return -tf.math.reduce_sum((temp1 + temp2))
def GCCE_MA_loss(self, y_true, y_pred):
# print(y_true,y_pred)
# q = 0.1
pred = y_pred[:, self.R:]
pred = tf.clip_by_value(pred, clip_value_min=1e-9, clip_value_max=1)
ann_ = y_pred[:, :self.R]
# ann_ = tf.clip_by_value(ann_, clip_value_min=1e-9, clip_value_max=1-1e-9)
Y_true = tf.one_hot(tf.cast(y_true, dtype=tf.int32), depth=self.K, axis=1)
Y_hat = tf.repeat(tf.expand_dims(pred,-1), self.R, axis = -1)
p_gcce = Y_true*(1 - Y_hat**self.q)/self.q
temp1 = ann_*tf.math.reduce_sum(p_gcce, axis=1)
# p_logreg = tf.math.reduce_prod(tf.math.pow(Y_hat, Y_true), axis=1)
# temp1 = ann_*tf.math.log(p_logreg)
# temp2 = (1 - ann_)*tf.math.log(1/K)*tf.reduce_sum(Y_true,axis=1)
# aux = tf.repeat(tf.reduce_sum(pred*tf.math.log(pred),axis=1,keepdims=True), R, axis = 1)
# tf.print(tf.shape(aux))
# print(tf.shape(aux))
# temp2 = (1 - ann_)*aux*tf.reduce_sum(Y_true,axis=1)
# temp2 = (tf.ones(tf.shape(ann_)) - ann_)*tf.math.log(1/K)
# print(tf.reduce_mean(Y_true,axis=1).numpy())
# Y_true_1 = tf.clip_by_value(Y_true, clip_value_min=1e-9, clip_value_max=1)
# p_logreg_inv = tf.math.reduce_prod(tf.math.pow(Y_true_1, Y_hat), axis=1)
# temp2 = (1 - ann_)*tf.math.log(p_logreg_inv)
temp2 = (1 - ann_)*(1-(1/self.K)**self.q)/self.q*tf.reduce_sum(Y_true,axis=1)
return tf.math.reduce_sum((temp1 + temp2))
def PRI_MA_loss(self, y_true, y_pred): #, -> PRI
#Input ytrue: samples (N) x annotators (R)
#Input ypred: samples (N) x annotators+classes (R+K)
#PRI MA
cce_M = tf.keras.losses.CategoricalCrossentropy(reduction='none',axis=-1)
cce_C = tf.keras.losses.CategoricalCrossentropy(reduction='none',axis=1)
#N = tf.cast(y_true.shape[0],dtype=tf.int32)
N = tf.shape(y_true)[0]
#Ground truth estimation samples (N) x Classes(K)
y_pred_tf = y_pred[:,self.R:]
# Annotators reliability prediction: samples (N) x annotators (R)
lambda_R_tf = y_pred[:,:self.R] #tf.ones(shape=(N,R))
#Y_true 1 K: samples (N) x Classes(1-K), annotators (R)
Y_true_1K = tf.one_hot(tf.cast(y_true,dtype=tf.int32),depth=self.K,axis=1)
#Y_pred 1 - K: samples (N) x Classes(1-K), annotators (R)
Y_hat = tf.repeat(tf.expand_dims(y_pred_tf,-1), self.R, axis = -1)
#marginal entropy
#cce along the K classes -> ypred_tf
Hm_ = cce_M(y_pred_tf,y_pred_tf)
#cross entropy
#cce along the K classes -> Y_hat
Hc_ = cce_C(Y_true_1K,Y_hat)
#PRI MA computation
LH = tf.linalg.matmul(lambda_R_tf,Hc_,transpose_a=True) # \Lambda^\top H_c
temp1 = tf.linalg.trace(LH) #trace(LH)
Hm1L = tf.linalg.matmul(tf.ones(shape=(N,self.R))-lambda_R_tf,tf.ones(shape=(self.R,1)))# 1_N 1_R^\top - Lambda
Hm_t = tf.reshape(Hm_,shape=(N,1))
temp2 = tf.squeeze(tf.linalg.matmul(Hm_t,Hm1L,transpose_a=True)) # Hm^\top Hm1L
loss_c = temp1+ temp2 #return loss
return loss_c
def fit(self, X, Y):
#input X numpy array first dimension samples (N)x features (P)
#input Y numpy array vector len = samples (N) x annotators (R)
P = X.shape[1]
if self.optimizer == "Adam":
opt = tf.keras.optimizers.Adam(learning_rate=self.learning_rate, clipnorm=1.0)
elif self.optimizer == "SGD":
opt = tf.keras.optimizers.SGD(learning_rate=self.learning_rate, clipnorm=1.0)
else:
opt=self.optimizer
#capa de entrada
input_l = tf.keras.layers.Input(shape=(X_train.shape[1]), name='entrada')
#capas densas
h1 = tf.keras.layers.Dense(int(P*4*(self.K+self.R)),activation='selu',name='h1',
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param,l2=self.l2_param))(input_l)#argumento de entrada
h2 = tf.keras.layers.Dense(int(P*(self.K+self.R)),activation='selu',name='h2',
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param,l2=self.l2_param))(h1)
dout = tf.keras.layers.Dropout(rate=self.dropout)(h2)
output_R = tf.keras.layers.Dense(self.R,activation="sigmoid",
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param,l2=self.l2_param), name= 'out_R_RCDNN' )(dout)
output_K = tf.keras.layers.Dense(self.K,activation="softmax",
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=self.l1_param,l2=self.l2_param), name= 'out_K_RCDNN')(dout)
output = tf.keras.layers.concatenate([output_R, output_K])
self.model = tf.keras.Model(inputs= input_l,outputs=output)
self.model.compile(loss=self.GCCE_MA_loss, optimizer=opt)
self.history = self.model.fit(X, Y, epochs=self.epochs, validation_split=self.validation_split, #
batch_size=self.batch_size,verbose=self.verbose)
return self
def predict(self, X, *_):
#input X numpy array first dimension samples (N)x features (P)
return self.model.predict(X)
def fit_predict(self,X,y):
#input X numpy array first dimension samples (N)x features (P)
#input Y numpy array vector len = samples (N) x annotators (R)
self.fit(X,y)
return self.predict(X)
#graphics
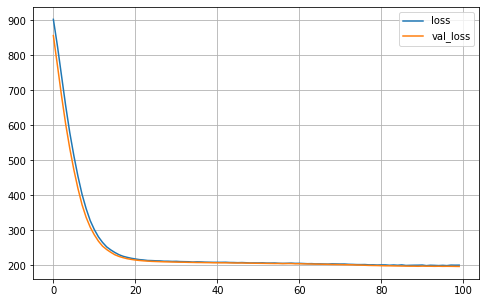
def plot_history(self):
pd.DataFrame(self.history.history).plot(figsize=(8, 5))
plt.grid(True)
#plt.gca().set_ylim(0, 1)
#save_fig("keras_learning_curves_plot")
plt.show()
return
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def get_params(self, deep=True):
return { 'l1_param':self.l1_param, 'dropout':self.dropout, 'optimizer':self.optimizer,
'learning_rate':self.learning_rate, 'batch_size':self.batch_size,
'epochs':self.epochs, 'verbose':self.verbose, 'validation_split':self.validation_split,
'R':self.R, 'K':self.K, 'q':self.q
}
return self
[31]:
#cargar datos desde drive acceso libre
FILEID = "1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW"
#https://drive.google.com/file/d/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O MADatasets.zip && rm -rf /tmp/cookies.txt
!unzip -o MADatasets.zip
!dir
--2023-02-13 18:02:30-- https://docs.google.com/uc?export=download&confirm=t&id=1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW
Resolving docs.google.com (docs.google.com)... 142.250.31.138, 142.250.31.101, 142.250.31.139, ...
Connecting to docs.google.com (docs.google.com)|142.250.31.138|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/aeiaeb4i20a9ib11lrj243e5c9n8n7gi/1676311350000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=fbb4c475-bcbd-4f96-81e5-4c98e20935e7 [following]
Warning: wildcards not supported in HTTP.
--2023-02-13 18:02:30-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/aeiaeb4i20a9ib11lrj243e5c9n8n7gi/1676311350000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=fbb4c475-bcbd-4f96-81e5-4c98e20935e7
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 142.251.163.132, 2607:f8b0:4004:c1b::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|142.251.163.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 156530728 (149M) [application/zip]
Saving to: ‘MADatasets.zip’
MADatasets.zip 100%[===================>] 149.28M 116MB/s in 1.3s
2023-02-13 18:02:32 (116 MB/s) - ‘MADatasets.zip’ saved [156530728/156530728]
Archive: MADatasets.zip
inflating: MADatasets/util.py
inflating: MADatasets/Iris1.mat
inflating: MADatasets/Integra_Labels.mat
inflating: MADatasets/MAGenerationClassification.py
inflating: MADatasets/Voice.mat
inflating: MADatasets/Iris.mat
inflating: MADatasets/Sinthetic.mat
inflating: MADatasets/MAGenerationClassification_1.py
inflating: MADatasets/Bupa1.mat
inflating: MADatasets/TicTacToe1.mat
inflating: MADatasets/Wine.mat
inflating: MADatasets/Breast1.mat
inflating: MADatasets/Breast.mat
inflating: MADatasets/Music.mat
inflating: MADatasets/Pima.mat
inflating: MADatasets/Ionosphere.mat
inflating: MADatasets/TicTacToe.mat
inflating: MADatasets/VoiceData.m
inflating: MADatasets/util_1.py
inflating: MADatasets/Ionosphere1.mat
inflating: MADatasets/__pycache__/util_1.cpython-37.pyc
inflating: MADatasets/Bupa.mat
inflating: MADatasets/Wine1.mat
inflating: MADatasets/__pycache__/util.cpython-37.pyc
inflating: MADatasets/Pima1.mat
inflating: MADatasets/Segmentation1.mat
inflating: MADatasets/Western.mat
inflating: MADatasets/Integra_Preprocesamiento_Seg_Caracterizacion_time_frec.mat
inflating: MADatasets/Western1.mat
inflating: MADatasets/Segmentation.mat
inflating: MADatasets/Skin_NonSkin.mat
inflating: MADatasets/Skin_NonSkin1.mat
inflating: MADatasets/Occupancy1.mat
inflating: MADatasets/Polarity.mat
inflating: MADatasets/Occupancy.mat
balance-scale.csv GCCE_TEST new-thyroid.csv TicTacToeGCE.xlsx
DataGCCE.zip MADatasets sample_data
file.csv MADatasets.zip tic-tac-toe-endgame.csv
Load Data¶
[32]:
#load data
import scipy.io as sio
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf #importar tensorflow
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import numpy as np
database = 'TicTacToe'
data = pd.read_csv('/content/tic-tac-toe-endgame.csv')
[33]:
def onehot_encode(df, columns):
df = df.copy()
for column in columns:
dummies = pd.get_dummies(df[column], prefix=column)
df = pd.concat([df, dummies], axis=1)
df = df.drop(column, axis=1)
return df
def preprocess_inputs(df):
df = df.copy()
# Encode label values as numbers
df['V10'] = df['V10'].replace({'negative': 0, 'positive': 1})
# One-hot encode board space columns
df = onehot_encode(
df,
columns=['V' + str(i) for i in range(1, 10)]
)
# Split df into X and y
y = df['V10'].copy()
X = df.drop('V10', axis=1).copy()
# Train-test split
# X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=123)
return X, y
[34]:
X, t = preprocess_inputs(data)
[35]:
X = np.array(X.values)
X
[35]:
array([[0, 0, 1, ..., 0, 1, 0],
[0, 0, 1, ..., 0, 1, 0],
[0, 0, 1, ..., 0, 0, 1],
...,
[0, 1, 0, ..., 0, 0, 1],
[0, 1, 0, ..., 0, 0, 1],
[0, 1, 0, ..., 0, 0, 1]], dtype=uint8)
[36]:
t = np.array(t.values)
t
[36]:
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
[37]:
t =t+1
t
[37]:
array([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
Labels Generation¶
[38]:
import random
import warnings
import numpy as np
#import climin
from functools import partial
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
#Defining the Sigmoid function and Softmax function
def Sigmoid(f_r):
lam_r = 1/(1 + np.exp(-f_r))
return lam_r
def MAjVot(Y, K):
N,R = Y.shape
Yhat = np.zeros((N,1))
for n in range(N):
votes = np.zeros((K,1))
for r in range(R):
for k in range(K):
if Y[n,r] == k+1:
votes[k] = votes[k]+1
Yhat[n] = np.argmax(votes) + 1
return Yhat
def MA_Clas_Gen(Xtrain,ytrain,R,NrP):
N = len(ytrain)
K = len(np.unique(ytrain))
Kn = np.unique(ytrain)
aux = 0
A = np.zeros((K,1))
for k in Kn:
A[aux] = (ytrain == k).sum()
aux = aux + 1
per = np.min(A)
if N < 25000:
Xtrain = TSNE(n_components=1,perplexity=per/2).fit_transform(Xtrain)
else:
Xtrain = np.sum(Xtrain,1)
# Xtrain = Xtrain-Xtrain.min()
# Xtrain = Xtrain/Xtrain.max()
#ytrain = y
# scaler = StandardScaler()
# scalerY = scaler.fit(y)
# ytrain = scaler.fit_transform(y)
#miny = y.min()
#ytrain = y-miny
#maxy = ytrain.max()
#ytrain = ytrain/maxy
# Xtrain = np.sum(Xtrain, axis=1)
Xtrain = Xtrain - Xtrain.min()
#print(Xtrain.min(), Xtrain.max())
Xtrain = Xtrain/Xtrain.max()
Xtrain = Xtrain.reshape((N,1))
yprueba = np.ones((N,1))
u_q = np.empty((Xtrain.shape[0],3))
u_q[:,0,None] = 4.5*np.cos(2*np.pi*Xtrain + 1.5*np.pi) - \
3*np.sin(4.3*np.pi*Xtrain + 0.3*np.pi)
u_q[:,1,None] = 4.5*np.cos(1.5*np.pi*Xtrain + 0.5*np.pi) + \
5*np.sin(3*np.pi*Xtrain + 1.5*np.pi)
u_q[:,2,None] = 1
W = []
# q=1
Wq1 = np.array(([[0.4],[0.7],[-0.5],[0],[-0.7]]))
W.append(Wq1)
# q=2
Wq2 = np.array(([[0.4],[-1.0],[-0.1],[-0.8],[1.0]]))
W.append(Wq2)
Wq3 = np.array(([[3.1],[-1.8],[-0.6],[-1.2],[1.0]]))
W.append(Wq3)
F_r = []
Lam_r = []
for r in range(R):
f_r = np.zeros((Xtrain.shape[0], 1))
# rho_r = np.zeros((Xtrain.shape[0], 1))
for q in range(3):
f_r += W[q][r].T*u_q[:,q,None]
F_r.append(f_r)
lam_r = Sigmoid(f_r)
lam_r[lam_r>0.5] = 1
lam_r[lam_r<=0.5] = 0
Lam_r.append(lam_r)
plt.plot(Xtrain,Lam_r[2],'rx')
plt.show()
seed = 0
np.random.seed(seed)
Ytrain = np.ones((N, R))
for r in range(R):
aux = ytrain.copy()
for n in range(N):
if Lam_r[r][n] == 0:
labels = np.arange(1, K+1)
a = np.where(labels==ytrain[n])
labels = np.delete(labels, a)
idxlabels = np.random.permutation(K-1)
aux[n] = labels[idxlabels[0]]
Ytrain[:,r] = aux.flatten()
# Ytrain = (Ytrain*maxy) + miny
iAnn = np.zeros((N, R), dtype=int) # this indicates if the annotator r labels the nth sample.
Nr = np.ones((R), dtype=int)*int(np.floor(N*NrP))
for r in range(R):
if r < R-1:
indexR = np.random.permutation(range(N))[:Nr[r]]
iAnn[indexR,r] = 1
else:
iSimm = np.sum(iAnn, axis=1)
idxZero = np.asarray([i for (i, val) in enumerate(iSimm) if val == 0])
Nzeros = idxZero.shape[0]
idx2Choose = np.arange(N)
if Nzeros == 0:
indexR = np.random.permutation(range(N))[:Nr[r]]
iAnn[indexR,r] = 1
else:
idx2Choose = np.delete(idx2Choose, idxZero)
N2chose = idx2Choose.shape[0]
idxNoZero = np.random.permutation(N2chose)[:(Nr[r] - Nzeros)]
idxTot = np.concatenate((idxZero, idx2Choose[idxNoZero]))
iAnn[idxTot,r] = 1
# Now, we verify that all the samples were labeled at least once
Nr = (np.sum(iAnn,0))
iSimm = np.sum(iAnn, axis=1)
if np.asarray([i for (i, val) in enumerate(iSimm) if val == 0]).sum() == 0:
ValueError("all the samples must be labeled at least once")
# Finally, if iAnn=0 we assign a reference value to indicate a missing value
Vref = -1e-20
for r in range(R):
Ytrain[iAnn[:,r] == 0, r] = Vref
return Ytrain, iAnn, Lam_r
def CrossVal(X, pp, Nk):
N = X.shape[0]
Ntr = int(N*pp)
Nte = N - Ntr
idxtr = np.zeros((Ntr,Nk))
idxte = np.zeros((Nte,Nk))
for i in range(Nk):
index = np.random.permutation(range(N))
idxtr[:,i] = index[:Ntr]
idxte[:,i] = index[Ntr:]
return idxtr, idxte
[39]:
Y, iAnn, Lam_r = MA_Clas_Gen(X ,t, R=5, NrP=1)
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:780: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:790: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(

[40]:
Y = Y - 1
t = t - 1
[41]:
from sklearn.metrics import classification_report
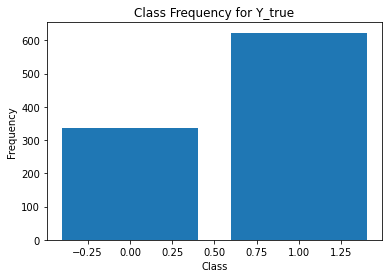
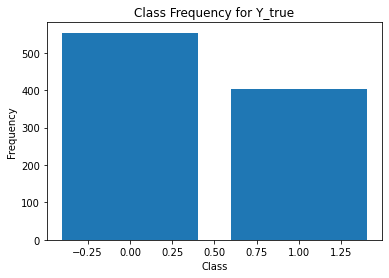
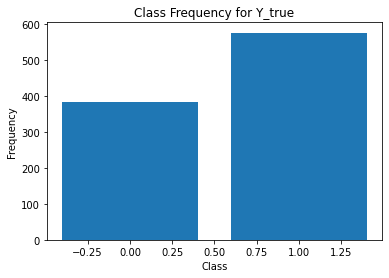
for i in range(Y.shape[1]):
print('annotator',i+1)
print(classification_report(t,Y[:,i]))
unique, counts = np.unique(Y[:,i], return_counts=True)
plt.figure()
plt.bar(unique, counts)
# unique, counts = np.unique(Y_test[5], return_counts=True)
# plt.bar(unique, counts)
plt.title('Class Frequency for Y_true')
plt.xlabel('Class')
plt.ylabel('Frequency')
annotator 1
precision recall f1-score support
0 0.79 0.80 0.80 332
1 0.89 0.89 0.89 626
accuracy 0.86 958
macro avg 0.84 0.85 0.84 958
weighted avg 0.86 0.86 0.86 958
annotator 2
precision recall f1-score support
0 0.44 0.73 0.55 332
1 0.78 0.50 0.61 626
accuracy 0.58 958
macro avg 0.61 0.62 0.58 958
weighted avg 0.66 0.58 0.59 958
annotator 3
precision recall f1-score support
0 0.47 0.54 0.50 332
1 0.73 0.67 0.70 626
accuracy 0.63 958
macro avg 0.60 0.61 0.60 958
weighted avg 0.64 0.63 0.63 958
annotator 4
precision recall f1-score support
0 0.37 0.50 0.43 332
1 0.68 0.55 0.60 626
accuracy 0.53 958
macro avg 0.52 0.53 0.52 958
weighted avg 0.57 0.53 0.54 958
annotator 5
precision recall f1-score support
0 0.11 0.16 0.13 332
1 0.38 0.27 0.31 626
accuracy 0.23 958
macro avg 0.24 0.22 0.22 958
weighted avg 0.28 0.23 0.25 958


Split data¶
[42]:
import numpy.matlib
from sklearn.model_selection import ShuffleSplit, StratifiedShuffleSplit
Ns = 1
ss = ShuffleSplit(n_splits=Ns, test_size=0.3,random_state =123)
for train_index, test_index in ss.split(X):
print(test_index)
X_train, X_test,Y_train,Y_test = X[train_index,:], X[test_index,:],Y[train_index,:], Y[test_index,:]
Y_true_train, Y_true_test = t[train_index].reshape(-1,1), t[test_index].reshape(-1,1)
print(X_train.shape, Y_train.shape, Y_true_train.shape)
[246 188 392 518 854 291 802 164 674 861 863 606 138 7 203 525 204 770
343 185 591 663 774 914 270 455 900 161 261 353 396 260 210 524 752 147
605 907 925 363 453 316 735 566 883 818 568 318 684 85 267 370 252 773
789 683 376 660 715 565 878 5 677 571 167 41 184 200 272 814 732 893
731 719 458 689 48 795 131 701 172 775 195 955 35 832 613 134 885 426
4 753 478 415 381 650 399 430 50 888 882 617 328 560 280 227 274 388
546 598 57 687 926 338 417 52 279 913 303 55 384 28 336 314 145 758
103 114 500 706 345 811 512 54 117 619 171 462 348 221 31 444 610 36
804 727 421 643 844 327 100 884 897 162 644 275 483 809 892 738 760 78
463 659 306 79 177 369 310 904 351 346 229 91 170 920 90 75 372 929
299 855 521 874 273 859 239 898 694 236 678 209 335 196 648 776 13 74
889 249 461 59 690 456 437 151 567 11 858 769 856 285 692 733 95 797
623 833 754 798 726 877 793 269 368 903 387 739 266 551 235 317 729 182
374 666 107 482 97 767 538 43 908 944 781 226 156 447 953 805 352 416
825 927 662 102 710 389 641 810 918 294 298 931 237 397 425 875 849 896
693 240 947 725 561 178 699 243 548 202 545 230 166 624 724 263 300 232]
(670, 27) (670, 5) (670, 1)
Apply MinMaxScaler¶
[43]:
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Testing the Class¶
[51]:
from sklearn.metrics import classification_report, balanced_accuracy_score, roc_auc_score
from sklearn.metrics import normalized_mutual_info_score, mutual_info_score, adjusted_mutual_info_score
import pandas as pd
l1 =0.1
NUM_RUNS =10
custom_loss = "GCE"
results = []
for i in range(NUM_RUNS):
print("iteration: " + str(i))
MA = Keras_MA_RCDNN(epochs=100,batch_size=64,R=5, K=len(np.unique(Y_true_train)), dropout=0.5, learning_rate=0.001,optimizer='Adam',
l1_param=l1, validation_split=0.30, verbose=0, q=0.1)
# MA = Keras_MA_GCCE(epochs=100,batch_size=32,R=5, K=len(np.unique(Y_true_train)), dropout=0.25, learning_rate=0.01,optimizer='Adam',
# l1_param=l1, validation_split=0, verbose=0, q=0.1, neurons=4, loss = custom_loss )
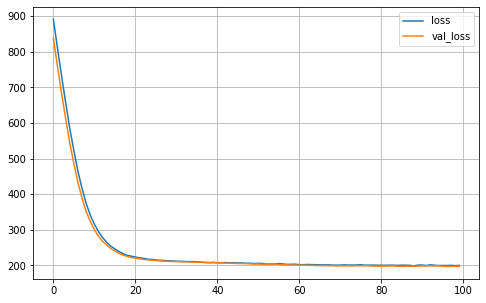
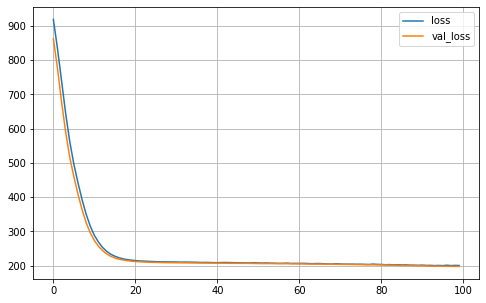
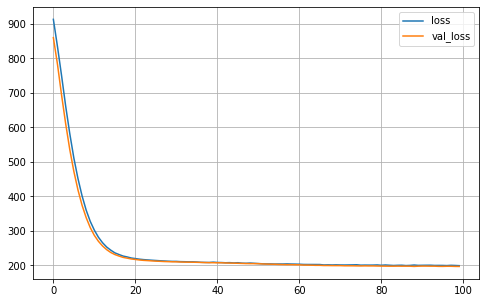
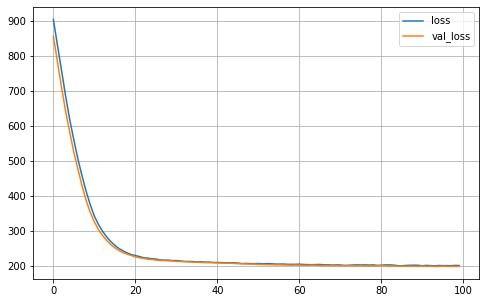
MA.fit(X_train, Y_train)
MA.plot_history()
# Generate the predictions for the current run
pred_2 = MA.predict(X_test)
acc, auc, auc_sk, nmi, bacc = evaluation_metrics(Y_true_test, pred_2[:,Y.shape[1]:], print_result=False) # mi, ami,
# Save the results for the current run to the list of dictionaries
results.append({
#'run': i,
'accuracy': acc,
'balanced_accuracy': bacc,
# 'mutual_information': mi,
'normalized_mutual_information': nmi,
# 'adjusted_mutual_information': ami,
'auc_tensorflow': auc,
'auc_scikit_learn': auc_sk,
})
# Convert the list of dictionaries to a DataFrame
df = np.round(pd.DataFrame(results)*100, 2)
# Calculate the mean and standard deviation of each metric
mean = np.round(df.mean(),2)
std = np.round(df.std(),2)
iteration: 0

9/9 [==============================] - 0s 2ms/step
iteration: 1
9/9 [==============================] - 0s 3ms/step
iteration: 2

9/9 [==============================] - 0s 3ms/step
iteration: 3
9/9 [==============================] - 0s 2ms/step
iteration: 4
9/9 [==============================] - 0s 3ms/step
iteration: 5

9/9 [==============================] - 0s 3ms/step
iteration: 6
9/9 [==============================] - 0s 2ms/step
iteration: 7
9/9 [==============================] - 0s 3ms/step
iteration: 8
9/9 [==============================] - 0s 3ms/step
iteration: 9

9/9 [==============================] - 0s 3ms/step
[52]:
df
[52]:
| accuracy | balanced_accuracy | normalized_mutual_information | auc_tensorflow | auc_scikit_learn | |
|---|---|---|---|---|---|
| 0 | 84.72 | 70.75 | 38.74 | 85.379997 | 93.95 |
| 1 | 88.89 | 73.87 | 48.58 | 86.940002 | 93.99 |
| 2 | 90.28 | 76.46 | 53.77 | 88.230003 | 94.26 |
| 3 | 89.93 | 80.93 | 53.16 | 90.459999 | 95.38 |
| 4 | 81.25 | 56.56 | 28.21 | 78.279999 | 89.12 |
| 5 | 85.42 | 73.31 | 42.16 | 86.650002 | 95.08 |
| 6 | 92.01 | 84.28 | 59.20 | 92.139999 | 95.74 |
| 7 | 90.28 | 78.62 | 52.35 | 89.309998 | 94.57 |
| 8 | 94.10 | 86.56 | 66.65 | 93.279999 | 95.66 |
| 9 | 93.75 | 85.64 | 65.32 | 92.820000 | 95.70 |
[53]:
mean
[53]:
accuracy 89.06
balanced_accuracy 76.70
normalized_mutual_information 50.81
auc_tensorflow 88.35
auc_scikit_learn 94.34
dtype: float64
[54]:
std
[54]:
accuracy 4.12
balanced_accuracy 8.92
normalized_mutual_information 11.95
auc_tensorflow 4.46
auc_scikit_learn 1.97
dtype: float64
[55]:
result_df = pd.concat([mean.rename('Mean'), std.rename('Std')], axis=1)
[56]:
result_df
[56]:
| Mean | Std | |
|---|---|---|
| accuracy | 89.06 | 4.12 |
| balanced_accuracy | 76.70 | 8.92 |
| normalized_mutual_information | 50.81 | 11.95 |
| auc_tensorflow | 88.35 | 4.46 |
| auc_scikit_learn | 94.34 | 1.97 |
[57]:
# Save the DataFrame to an excel file
result_df.to_excel(database + custom_loss + ".xlsx")
[ ]: