![]()
[1]:
import tensorflow as tf
from sklearn.metrics import classification_report, accuracy_score, balanced_accuracy_score, roc_auc_score, mutual_info_score, normalized_mutual_info_score, adjusted_mutual_info_score
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import numpy as np
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
def evaluation_metrics(y_true, y_pred, print_result=True):
acc = 0
auc = 0
auc_sk = 0
#mi = 0
nmi = 0
#ami = 0
bacc = 0
# Accuracy
#report = classification_report(y_pred.argmax(axis=1), y_true.ravel(), output_dict=True)
acc = accuracy_score( y_true.ravel(), y_pred.argmax(axis=1)) #report['accuracy']
# Balanced accuracy
bacc = balanced_accuracy_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze(), adjusted=True)
# # Mutual Information
# mi = mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Normalized Mutual Information
nmi = normalized_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Adjusted Mutual Information
#ami = adjusted_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# AUC (Tensorflow)
auc_metric = tf.keras.metrics.AUC(from_logits=True)
auc_metric.update_state(y_true, y_pred.argmax(axis=1).astype('float'))
auc = auc_metric.result().numpy()
auc_metric.reset_states()
# AUC (scikit-learn)
auc_sk = roc_auc_score(ook(y_true), y_pred)
if print_result:
print("Accuracy: {:.4f}".format(acc))
print("Balanced Accuracy: {:.4f}".format(bacc))
print("Mutual Information: {:.4f}".format(mi))
print("Normalized Mutual Information: {:.4f}".format(nmi))
print("Adjusted Mutual Information: {:.4f}".format(ami))
print("AUC (Tensorflow): {:.4f}".format(auc))
print("AUC (scikit-learn): {:.4f}".format(auc_sk))
return acc, auc, auc_sk, nmi, bacc # mi, , ami
Subclassing for RCDNN¶
[2]:
!git clone https://github.com/Jectrianama/GCCE_TEST.git
Cloning into 'GCCE_TEST'...
remote: Enumerating objects: 861, done.
remote: Counting objects: 100% (454/454), done.
remote: Compressing objects: 100% (238/238), done.
remote: Total 861 (delta 240), reused 397 (delta 210), pack-reused 407
Receiving objects: 100% (861/861), 38.84 MiB | 9.53 MiB/s, done.
Resolving deltas: 100% (408/408), done.
[3]:
import os
os.chdir('/content/GCCE_TEST/Models')
from keras_ma_gcce import *
from labels_generation import MA_Clas_Gen
os.chdir('../../')
[4]:
#cargar datos desde drive otros dataset
FILEID = "1AU8pTtCLihBjCZjWITaAzpnEuL4RO436"
#https://drive.google.com/file/d/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O DataGCCE.zip && rm -rf /tmp/cookies.txt
!unzip -o DataGCCE.zip
!dir
--2023-02-13 17:23:20-- https://docs.google.com/uc?export=download&confirm=&id=1AU8pTtCLihBjCZjWITaAzpnEuL4RO436
Resolving docs.google.com (docs.google.com)... 142.251.163.113, 142.251.163.100, 142.251.163.139, ...
Connecting to docs.google.com (docs.google.com)|142.251.163.113|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ejbc6j3nf9amr31o7n28lecb6ec6rd5c/1676308950000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=42cd46c3-8e3e-446b-9fc3-0dd6f32ac042 [following]
Warning: wildcards not supported in HTTP.
--2023-02-13 17:23:21-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ejbc6j3nf9amr31o7n28lecb6ec6rd5c/1676308950000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=42cd46c3-8e3e-446b-9fc3-0dd6f32ac042
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 172.253.115.132, 2607:f8b0:4004:c06::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|172.253.115.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 38377 (37K) [application/x-zip-compressed]
Saving to: ‘DataGCCE.zip’
DataGCCE.zip 100%[===================>] 37.48K --.-KB/s in 0s
2023-02-13 17:23:21 (87.3 MB/s) - ‘DataGCCE.zip’ saved [38377/38377]
Archive: DataGCCE.zip
inflating: new-thyroid.csv
inflating: tic-tac-toe-endgame.csv
inflating: balance-scale.csv
inflating: file.csv
balance-scale.csv file.csv new-thyroid.csv tic-tac-toe-endgame.csv
DataGCCE.zip GCCE_TEST sample_data
[5]:
#cargar datos desde drive acceso libre
FILEID = "1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW"
#https://drive.google.com/file/d/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O MADatasets.zip && rm -rf /tmp/cookies.txt
!unzip -o MADatasets.zip
!dir
--2023-02-13 17:23:21-- https://docs.google.com/uc?export=download&confirm=t&id=1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW
Resolving docs.google.com (docs.google.com)... 142.251.163.113, 142.251.163.100, 142.251.163.139, ...
Connecting to docs.google.com (docs.google.com)|142.251.163.113|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/crie1jtml02ra09q71kdq7ckgq4hj72h/1676308950000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=99eb878a-14f5-406d-b656-88d23bd48141 [following]
Warning: wildcards not supported in HTTP.
--2023-02-13 17:23:22-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/crie1jtml02ra09q71kdq7ckgq4hj72h/1676308950000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=99eb878a-14f5-406d-b656-88d23bd48141
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 172.253.115.132, 2607:f8b0:4004:c06::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|172.253.115.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 156530728 (149M) [application/zip]
Saving to: ‘MADatasets.zip’
MADatasets.zip 100%[===================>] 149.28M 65.7MB/s in 2.3s
2023-02-13 17:23:24 (65.7 MB/s) - ‘MADatasets.zip’ saved [156530728/156530728]
Archive: MADatasets.zip
inflating: MADatasets/util.py
inflating: MADatasets/Iris1.mat
inflating: MADatasets/Integra_Labels.mat
inflating: MADatasets/MAGenerationClassification.py
inflating: MADatasets/Voice.mat
inflating: MADatasets/Iris.mat
inflating: MADatasets/Sinthetic.mat
inflating: MADatasets/MAGenerationClassification_1.py
inflating: MADatasets/Bupa1.mat
inflating: MADatasets/TicTacToe1.mat
inflating: MADatasets/Wine.mat
inflating: MADatasets/Breast1.mat
inflating: MADatasets/Breast.mat
inflating: MADatasets/Music.mat
inflating: MADatasets/Pima.mat
inflating: MADatasets/Ionosphere.mat
inflating: MADatasets/TicTacToe.mat
inflating: MADatasets/VoiceData.m
inflating: MADatasets/util_1.py
inflating: MADatasets/Ionosphere1.mat
inflating: MADatasets/__pycache__/util_1.cpython-37.pyc
inflating: MADatasets/Bupa.mat
inflating: MADatasets/Wine1.mat
inflating: MADatasets/__pycache__/util.cpython-37.pyc
inflating: MADatasets/Pima1.mat
inflating: MADatasets/Segmentation1.mat
inflating: MADatasets/Western.mat
inflating: MADatasets/Integra_Preprocesamiento_Seg_Caracterizacion_time_frec.mat
inflating: MADatasets/Western1.mat
inflating: MADatasets/Segmentation.mat
inflating: MADatasets/Skin_NonSkin.mat
inflating: MADatasets/Skin_NonSkin1.mat
inflating: MADatasets/Occupancy1.mat
inflating: MADatasets/Polarity.mat
inflating: MADatasets/Occupancy.mat
balance-scale.csv GCCE_TEST new-thyroid.csv
DataGCCE.zip MADatasets sample_data
file.csv MADatasets.zip tic-tac-toe-endgame.csv
Load Data¶
[6]:
#load data
import scipy.io as sio
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf #importar tensorflow
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import numpy as np
database = 'Ocupancy'#['bupa1', 'breast-cancer-wisconsin1','pima-indians-diabetes1', 'ionosphere1', 'tic-tac-toe1', 'iris1', 'wine1', 'segmentation1']
import pandas as pd
from sklearn.preprocessing import LabelEncoder
dfo= pd.read_csv(r'/content//file.csv')
dfo
#Removing the HumidityRatio attribute which is least correlated to the target attribute
t=dfo['Occupancy'].values
X = dfo.drop(['HumidityRatio','Occupancy'], axis = 1).values
t=t+1
Labels Generation¶
[7]:
import random
import warnings
import numpy as np
#import climin
from functools import partial
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
#Defining the Sigmoid function and Softmax function
def Sigmoid(f_r):
lam_r = 1/(1 + np.exp(-f_r))
return lam_r
def MAjVot(Y, K):
N,R = Y.shape
Yhat = np.zeros((N,1))
for n in range(N):
votes = np.zeros((K,1))
for r in range(R):
for k in range(K):
if Y[n,r] == k+1:
votes[k] = votes[k]+1
Yhat[n] = np.argmax(votes) + 1
return Yhat
def MA_Clas_Gen(Xtrain,ytrain,R,NrP):
N = len(ytrain)
K = len(np.unique(ytrain))
Kn = np.unique(ytrain)
aux = 0
A = np.zeros((K,1))
for k in Kn:
A[aux] = (ytrain == k).sum()
aux = aux + 1
per = np.min(A)
if N < 25000:
Xtrain = TSNE(n_components=1,perplexity=per/2).fit_transform(Xtrain)
else:
Xtrain = np.sum(Xtrain,1)
# Xtrain = Xtrain-Xtrain.min()
# Xtrain = Xtrain/Xtrain.max()
#ytrain = y
# scaler = StandardScaler()
# scalerY = scaler.fit(y)
# ytrain = scaler.fit_transform(y)
#miny = y.min()
#ytrain = y-miny
#maxy = ytrain.max()
#ytrain = ytrain/maxy
# Xtrain = np.sum(Xtrain, axis=1)
Xtrain = Xtrain - Xtrain.min()
#print(Xtrain.min(), Xtrain.max())
Xtrain = Xtrain/Xtrain.max()
Xtrain = Xtrain.reshape((N,1))
yprueba = np.ones((N,1))
u_q = np.empty((Xtrain.shape[0],3))
u_q[:,0,None] = 4.5*np.cos(2*np.pi*Xtrain + 1.5*np.pi) - \
3*np.sin(4.3*np.pi*Xtrain + 0.3*np.pi)
u_q[:,1,None] = 4.5*np.cos(1.5*np.pi*Xtrain + 0.5*np.pi) + \
5*np.sin(3*np.pi*Xtrain + 1.5*np.pi)
u_q[:,2,None] = 1
W = []
# q=1
Wq1 = np.array(([[0.4],[0.7],[-0.5],[0],[-0.7]]))
W.append(Wq1)
# q=2
Wq2 = np.array(([[0.4],[-1.0],[-0.1],[-0.8],[1.0]]))
W.append(Wq2)
Wq3 = np.array(([[3.1],[-1.8],[-0.6],[-1.2],[1.0]]))
W.append(Wq3)
F_r = []
Lam_r = []
for r in range(R):
f_r = np.zeros((Xtrain.shape[0], 1))
# rho_r = np.zeros((Xtrain.shape[0], 1))
for q in range(3):
f_r += W[q][r].T*u_q[:,q,None]
F_r.append(f_r)
lam_r = Sigmoid(f_r)
lam_r[lam_r>0.5] = 1
lam_r[lam_r<=0.5] = 0
Lam_r.append(lam_r)
plt.plot(Xtrain,Lam_r[2],'rx')
plt.show()
seed = 0
np.random.seed(seed)
Ytrain = np.ones((N, R))
for r in range(R):
aux = ytrain.copy()
for n in range(N):
if Lam_r[r][n] == 0:
labels = np.arange(1, K+1)
a = np.where(labels==ytrain[n])
labels = np.delete(labels, a)
idxlabels = np.random.permutation(K-1)
aux[n] = labels[idxlabels[0]]
Ytrain[:,r] = aux.flatten()
# Ytrain = (Ytrain*maxy) + miny
iAnn = np.zeros((N, R), dtype=int) # this indicates if the annotator r labels the nth sample.
Nr = np.ones((R), dtype=int)*int(np.floor(N*NrP))
for r in range(R):
if r < R-1:
indexR = np.random.permutation(range(N))[:Nr[r]]
iAnn[indexR,r] = 1
else:
iSimm = np.sum(iAnn, axis=1)
idxZero = np.asarray([i for (i, val) in enumerate(iSimm) if val == 0])
Nzeros = idxZero.shape[0]
idx2Choose = np.arange(N)
if Nzeros == 0:
indexR = np.random.permutation(range(N))[:Nr[r]]
iAnn[indexR,r] = 1
else:
idx2Choose = np.delete(idx2Choose, idxZero)
N2chose = idx2Choose.shape[0]
idxNoZero = np.random.permutation(N2chose)[:(Nr[r] - Nzeros)]
idxTot = np.concatenate((idxZero, idx2Choose[idxNoZero]))
iAnn[idxTot,r] = 1
# Now, we verify that all the samples were labeled at least once
Nr = (np.sum(iAnn,0))
iSimm = np.sum(iAnn, axis=1)
if np.asarray([i for (i, val) in enumerate(iSimm) if val == 0]).sum() == 0:
ValueError("all the samples must be labeled at least once")
# Finally, if iAnn=0 we assign a reference value to indicate a missing value
Vref = -1e-20
for r in range(R):
Ytrain[iAnn[:,r] == 0, r] = Vref
return Ytrain, iAnn, Lam_r
def CrossVal(X, pp, Nk):
N = X.shape[0]
Ntr = int(N*pp)
Nte = N - Ntr
idxtr = np.zeros((Ntr,Nk))
idxte = np.zeros((Nte,Nk))
for i in range(Nk):
index = np.random.permutation(range(N))
idxtr[:,i] = index[:Ntr]
idxte[:,i] = index[Ntr:]
return idxtr, idxte
[8]:
Y, iAnn, Lam_r = MA_Clas_Gen(X ,t, R=5, NrP=1)
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:780: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:790: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(

[9]:
Y = Y - 1
t = t - 1
[10]:
from sklearn.metrics import classification_report
for i in range(Y.shape[1]):
print('annotator',i+1)
print(classification_report(t,Y[:,i]))
unique, counts = np.unique(Y[:,i], return_counts=True)
plt.figure()
plt.bar(unique, counts)
# unique, counts = np.unique(Y_test[5], return_counts=True)
# plt.bar(unique, counts)
plt.title('Class Frequency for Y_true')
plt.xlabel('Class')
plt.ylabel('Frequency')
annotator 1
precision recall f1-score support
0 1.00 0.76 0.86 1693
1 0.71 1.00 0.83 972
accuracy 0.85 2665
macro avg 0.85 0.88 0.85 2665
weighted avg 0.89 0.85 0.85 2665
annotator 2
precision recall f1-score support
0 1.00 0.33 0.50 1693
1 0.46 1.00 0.63 972
accuracy 0.58 2665
macro avg 0.73 0.67 0.57 2665
weighted avg 0.80 0.58 0.55 2665
annotator 3
precision recall f1-score support
0 0.74 0.96 0.84 1693
1 0.85 0.41 0.56 972
accuracy 0.76 2665
macro avg 0.80 0.69 0.70 2665
weighted avg 0.78 0.76 0.73 2665
annotator 4
precision recall f1-score support
0 0.81 0.46 0.59 1693
1 0.46 0.81 0.59 972
accuracy 0.59 2665
macro avg 0.64 0.64 0.59 2665
weighted avg 0.69 0.59 0.59 2665
annotator 5
precision recall f1-score support
0 0.48 0.54 0.51 1693
1 0.00 0.00 0.00 972
accuracy 0.34 2665
macro avg 0.24 0.27 0.26 2665
weighted avg 0.31 0.34 0.32 2665

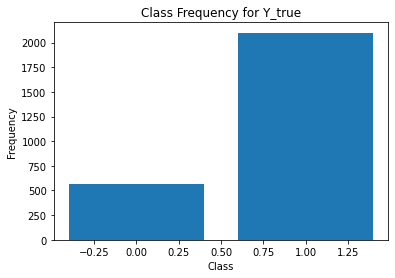

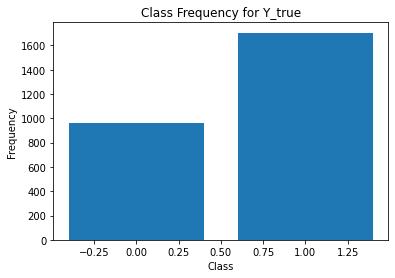
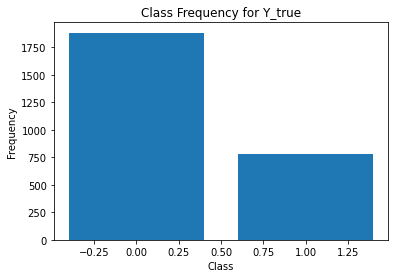
Split data¶
[11]:
import numpy.matlib
from sklearn.model_selection import ShuffleSplit, StratifiedShuffleSplit
Ns = 1
ss = ShuffleSplit(n_splits=Ns, test_size=0.3,random_state =123)
for train_index, test_index in ss.split(X):
print(test_index)
X_train, X_test,Y_train,Y_test = X[train_index,:], X[test_index,:],Y[train_index,:], Y[test_index,:]
Y_true_train, Y_true_test = t[train_index].reshape(-1,1), t[test_index].reshape(-1,1)
print(X_train.shape, Y_train.shape, Y_true_train.shape)
[ 315 235 1480 1538 1087 1009 1677 1094 343 2175 1455 2535 2641 798
417 2238 1781 1445 85 1828 2029 1034 1067 1458 2455 732 2434 2247
2113 2386 689 853 2200 2500 179 1245 1758 1927 709 1826 2529 1099
805 601 1022 1730 2135 1361 2294 2644 206 420 878 2093 1400 1518
934 1622 1279 613 957 190 33 1450 335 1371 2634 103 304 1228
2242 2384 1637 673 222 2340 1765 360 289 25 45 1937 537 1237
1183 2095 2375 2379 2390 2170 2607 589 1833 2628 354 189 2016 1286
1116 556 1918 937 1740 803 2435 257 807 1697 2494 2538 249 683
1673 1391 871 1064 1364 814 184 498 1898 1017 1055 906 645 242
684 779 784 1696 1226 423 966 2596 649 1008 2402 101 1283 1529
2417 1449 616 1107 1845 1011 1572 2525 2380 2651 704 1089 466 1853
2462 1726 2502 2479 1710 1050 469 220 336 263 1535 554 2590 1273
2543 861 449 1224 1957 2537 1106 114 1213 2194 830 973 1504 2168
777 1975 996 2025 2094 707 994 2315 1970 748 1982 2430 1511 43
2291 1822 1547 958 2312 1598 1733 1587 1659 856 1654 2028 2648 2627
148 1347 1624 1688 383 565 2572 2296 381 714 58 1032 2160 353
2021 1000 1788 2445 524 2331 2420 1191 1278 1113 208 132 1621 875
2400 319 800 646 2353 403 1205 1203 1685 364 129 1941 2039 1426
591 252 2048 1489 1247 477 1633 1036 1603 706 440 576 1821 1523
2561 2488 618 590 1362 1464 1945 395 2458 1556 2041 632 1527 720
2337 2116 1260 1915 2211 108 658 2096 1374 1717 897 2421 2512 2003
1809 310 1997 1394 949 2395 1706 1791 2223 2215 2047 2271 1536 243
1310 1351 21 850 1385 723 511 2067 785 970 1840 822 439 2064
1456 1178 2098 2410 2595 2164 1083 2622 2253 2155 1027 1206 2002 2437
680 1727 1955 1842 1678 647 1690 1739 547 1413 1102 476 2612 1578
1832 368 569 116 12 1227 1127 1416 2088 1907 1837 471 1373 270
1356 2505 742 1448 24 2358 594 1938 2459 1269 2657 1925 621 2404
1143 1015 1751 2626 493 31 2653 1430 518 221 431 1319 982 167
671 2138 792 1867 841 110 799 2246 2115 239 1928 2317 2264 379
1878 553 1959 1397 1611 1943 1983 224 75 2316 402 256 1002 746
2035 63 1375 1801 2144 1265 1689 2280 18 2601 1911 2078 1342 1330
2580 141 1383 2642 1103 328 2233 813 1066 2472 1605 1724 2598 610
127 2051 948 1193 971 2178 682 2165 1266 988 1599 730 1077 2258
2325 266 2092 207 2411 215 1195 1415 2469 895 1065 1167 2192 50
1166 1035 1186 1802 196 2262 2578 2554 1156 857 380 2209 767 638
1827 2143 2506 984 501 2456 627 2112 1208 1923 1964 2287 86 2374
976 419 1379 1952 1380 1298 1285 597 1233 1569 2303 2569 429 1676
1482 2332 502 1559 26 738 1117 2012 2134 2329 2102 1200 1920 1703
991 426 327 1701 835 2151 1912 1411 1600 2497 2368 2423 1737 2193
1910 1834 693 1090 1549 2288 352 2487 1216 558 1848 1144 2311 2083
28 2361 1814 1420 641 2489 1657 279 72 536 909 2157 112 891
1204 563 1098 1924 318 1046 735 797 2549 1037 1750 917 838 1042
675 216 2565 2589 529 1179 1097 1612 2621 326 1123 1462 120 2348
2292 5 30 2152 292 2084 1068 667 1743 1617 1471 351 749 91
1461 2623 1020 1412 2511 593 2544 2114 2425 2352 2158 1668 228 1854
903 2180 1671 1121 452 585 2239 2101 2214 615 463 1334 1469 1058
100 444 1721 1808 1476 1187 1360 1670 2049 1830 1451 1798 969 2486
2045 1052 633 1933 952 515 968 809 13 961 2310 717 1843 1051
981 2136 410 2053 421 1967 1119 2068 1976 388 198 1695 2522 2594
564 1446 2520 2243 2119 698 1012 2190 183 155 1340 2508 1623 500
188 1613 2133 2122 409 1344 2476 1043 2231 406 926 504 1463 1459
1256 775 118 804 1960 275 1306 611 1754 2454 2406 914 630 2658
2218 1308 7 820 2422 574 1779 595 204 728 276 1276 2440 1199
972 978 1483 1887 74 236 1234 187 1324 923 375 1805 349 350
776 2221 2228 2020 1773 1280 606 237 2091 715 623 546 1295 2324
84 1800 1079 1995 2279 756 2126 1473 882 2199 734 1440 157 1846
1155 1818 193 2367 1965 2081 995 2245 1573 229 56 2125 1700 458
1126 2278]
(1865, 4) (1865, 5) (1865, 1)
Apply MinMaxScaler¶
[12]:
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Testing the Class¶
[13]:
from sklearn.metrics import classification_report, balanced_accuracy_score, roc_auc_score
from sklearn.metrics import normalized_mutual_info_score, mutual_info_score, adjusted_mutual_info_score
import pandas as pd
l1 =0.01
NUM_RUNS =10
custom_loss = "GCE"
results = []
for i in range(NUM_RUNS):
print("iteration: " + str(i))
MA = Keras_MA_GCCE(epochs=50,batch_size=32,R=5, K=len(np.unique(Y_true_train)), dropout=0.25, learning_rate=0.01,optimizer='Adam',
l1_param=l1, validation_split=0, verbose=0, q=0.1, neurons=4, loss = custom_loss )
MA.fit(X_train, Y_train)
MA.plot_history()
# Generate the predictions for the current run
pred_2 = MA.predict(X_test)
acc, auc, auc_sk, nmi, bacc = evaluation_metrics(Y_true_test, pred_2[:,Y.shape[1]:], print_result=False) # mi, ami,
# Save the results for the current run to the list of dictionaries
results.append({
#'run': i,
'accuracy': acc,
'balanced_accuracy': bacc,
# 'mutual_information': mi,
'normalized_mutual_information': nmi,
# 'adjusted_mutual_information': ami,
'auc_tensorflow': auc,
'auc_scikit_learn': auc_sk,
})
# Convert the list of dictionaries to a DataFrame
df = np.round(pd.DataFrame(results)*100, 2)
# Calculate the mean and standard deviation of each metric
mean = np.round(df.mean(),2)
std = np.round(df.std(),2)
iteration: 0
25/25 [==============================] - 0s 1ms/step
iteration: 1
25/25 [==============================] - 0s 1ms/step
iteration: 2
25/25 [==============================] - 0s 2ms/step
iteration: 3
25/25 [==============================] - 0s 1ms/step
iteration: 4
25/25 [==============================] - 0s 1ms/step
iteration: 5

25/25 [==============================] - 0s 2ms/step
iteration: 6

25/25 [==============================] - 0s 1ms/step
iteration: 7
25/25 [==============================] - 0s 1ms/step
iteration: 8
25/25 [==============================] - 0s 1ms/step
iteration: 9

25/25 [==============================] - 0s 2ms/step
[14]:
df
[14]:
| accuracy | balanced_accuracy | normalized_mutual_information | auc_tensorflow | auc_scikit_learn | |
|---|---|---|---|---|---|
| 0 | 96.00 | 92.01 | 74.68 | 96.000000 | 98.90 |
| 1 | 96.12 | 92.37 | 75.37 | 96.180000 | 98.85 |
| 2 | 96.12 | 91.85 | 75.01 | 95.930000 | 98.84 |
| 3 | 95.38 | 90.37 | 71.53 | 95.180000 | 99.11 |
| 4 | 95.62 | 91.26 | 72.94 | 95.629997 | 99.00 |
| 5 | 97.12 | 94.58 | 80.62 | 97.290001 | 99.20 |
| 6 | 96.62 | 94.33 | 79.32 | 97.169998 | 98.99 |
| 7 | 95.62 | 91.26 | 72.94 | 95.629997 | 98.79 |
| 8 | 95.75 | 91.80 | 73.79 | 95.900002 | 98.72 |
| 9 | 96.50 | 93.97 | 78.42 | 96.989998 | 98.93 |
[15]:
mean
[15]:
accuracy 96.08
balanced_accuracy 92.38
normalized_mutual_information 75.46
auc_tensorflow 96.19
auc_scikit_learn 98.93
dtype: float64
[16]:
std
[16]:
accuracy 0.54
balanced_accuracy 1.43
normalized_mutual_information 3.02
auc_tensorflow 0.72
auc_scikit_learn 0.15
dtype: float64
[17]:
result_df = pd.concat([mean.rename('Mean'), std.rename('Std')], axis=1)
[18]:
result_df
[18]:
| Mean | Std | |
|---|---|---|
| accuracy | 96.08 | 0.54 |
| balanced_accuracy | 92.38 | 1.43 |
| normalized_mutual_information | 75.46 | 3.02 |
| auc_tensorflow | 96.19 | 0.72 |
| auc_scikit_learn | 98.93 | 0.15 |
[19]:
# Save the DataFrame to an excel file
result_df.to_excel(database + custom_loss + ".xlsx")