![]()
Subclassing for GCCE¶
[1]:
!git clone https://github.com/Jectrianama/GCCE_TEST.git
Cloning into 'GCCE_TEST'...
remote: Enumerating objects: 680, done.
remote: Counting objects: 100% (273/273), done.
remote: Compressing objects: 100% (146/146), done.
remote: Total 680 (delta 149), reused 215 (delta 122), pack-reused 407
Receiving objects: 100% (680/680), 30.82 MiB | 14.00 MiB/s, done.
Resolving deltas: 100% (317/317), done.
[2]:
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import numpy as np
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
[3]:
import os
os.chdir('/content/GCCE_TEST/Models')
from keras_ma_gcce import *
from labels_generation import MA_Clas_Gen
os.chdir('../../')
[4]:
#cargar datos desde drive otros dataset
FILEID = "1AU8pTtCLihBjCZjWITaAzpnEuL4RO436"
#https://drive.google.com/file/d/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O DataGCCE.zip && rm -rf /tmp/cookies.txt
!unzip -o DataGCCE.zip
!dir
--2023-02-11 05:25:35-- https://docs.google.com/uc?export=download&confirm=&id=1AU8pTtCLihBjCZjWITaAzpnEuL4RO436
Resolving docs.google.com (docs.google.com)... 142.250.101.139, 142.250.101.138, 142.250.101.100, ...
Connecting to docs.google.com (docs.google.com)|142.250.101.139|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/778i4gob0uu2erbek8f9uuhmcr1f8ac2/1676093100000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=513964b6-f89e-40ee-8aba-9e2ae9db894c [following]
Warning: wildcards not supported in HTTP.
--2023-02-11 05:25:36-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/778i4gob0uu2erbek8f9uuhmcr1f8ac2/1676093100000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=513964b6-f89e-40ee-8aba-9e2ae9db894c
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 142.251.2.132, 2607:f8b0:4023:c0d::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|142.251.2.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 38377 (37K) [application/x-zip-compressed]
Saving to: ‘DataGCCE.zip’
DataGCCE.zip 100%[===================>] 37.48K --.-KB/s in 0s
2023-02-11 05:25:36 (78.6 MB/s) - ‘DataGCCE.zip’ saved [38377/38377]
Archive: DataGCCE.zip
inflating: new-thyroid.csv
inflating: tic-tac-toe-endgame.csv
inflating: balance-scale.csv
inflating: file.csv
balance-scale.csv file.csv new-thyroid.csv tic-tac-toe-endgame.csv
DataGCCE.zip GCCE_TEST sample_data
[5]:
#cargar datos desde drive acceso libre
FILEID = "1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW"
#https://drive.google.com/file/d/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O MADatasets.zip && rm -rf /tmp/cookies.txt
!unzip -o MADatasets.zip
!dir
--2023-02-11 05:25:37-- https://docs.google.com/uc?export=download&confirm=t&id=1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW
Resolving docs.google.com (docs.google.com)... 142.250.101.139, 142.250.101.138, 142.250.101.100, ...
Connecting to docs.google.com (docs.google.com)|142.250.101.139|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/lv26o3em8uubspofb4qa7eb2m3o1413v/1676093100000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=677f5ecf-8725-4b26-ad63-ad557996bdb3 [following]
Warning: wildcards not supported in HTTP.
--2023-02-11 05:25:37-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/lv26o3em8uubspofb4qa7eb2m3o1413v/1676093100000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=677f5ecf-8725-4b26-ad63-ad557996bdb3
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 142.251.2.132, 2607:f8b0:4023:c0d::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|142.251.2.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 156530728 (149M) [application/zip]
Saving to: ‘MADatasets.zip’
MADatasets.zip 100%[===================>] 149.28M 85.9MB/s in 1.7s
2023-02-11 05:25:39 (85.9 MB/s) - ‘MADatasets.zip’ saved [156530728/156530728]
Archive: MADatasets.zip
inflating: MADatasets/util.py
inflating: MADatasets/Iris1.mat
inflating: MADatasets/Integra_Labels.mat
inflating: MADatasets/MAGenerationClassification.py
inflating: MADatasets/Voice.mat
inflating: MADatasets/Iris.mat
inflating: MADatasets/Sinthetic.mat
inflating: MADatasets/MAGenerationClassification_1.py
inflating: MADatasets/Bupa1.mat
inflating: MADatasets/TicTacToe1.mat
inflating: MADatasets/Wine.mat
inflating: MADatasets/Breast1.mat
inflating: MADatasets/Breast.mat
inflating: MADatasets/Music.mat
inflating: MADatasets/Pima.mat
inflating: MADatasets/Ionosphere.mat
inflating: MADatasets/TicTacToe.mat
inflating: MADatasets/VoiceData.m
inflating: MADatasets/util_1.py
inflating: MADatasets/Ionosphere1.mat
inflating: MADatasets/__pycache__/util_1.cpython-37.pyc
inflating: MADatasets/Bupa.mat
inflating: MADatasets/Wine1.mat
inflating: MADatasets/__pycache__/util.cpython-37.pyc
inflating: MADatasets/Pima1.mat
inflating: MADatasets/Segmentation1.mat
inflating: MADatasets/Western.mat
inflating: MADatasets/Integra_Preprocesamiento_Seg_Caracterizacion_time_frec.mat
inflating: MADatasets/Western1.mat
inflating: MADatasets/Segmentation.mat
inflating: MADatasets/Skin_NonSkin.mat
inflating: MADatasets/Skin_NonSkin1.mat
inflating: MADatasets/Occupancy1.mat
inflating: MADatasets/Polarity.mat
inflating: MADatasets/Occupancy.mat
balance-scale.csv GCCE_TEST new-thyroid.csv
DataGCCE.zip MADatasets sample_data
file.csv MADatasets.zip tic-tac-toe-endgame.csv
Load Data¶
[6]:
#load data
import scipy.io as sio
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf #importar tensorflow
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import numpy as np
database = 'Segmentation' #['bupa1', 'breast-cancer-wisconsin1','pima-indians-diabetes1', 'ionosphere1', 'tic-tac-toe1', 'iris1', 'wine1', 'segmentation1']
path_ = 'MADatasets/'+ database+ '.mat'
Xdata = sio.loadmat(path_)
Xdata.keys()
[6]:
dict_keys(['__header__', '__version__', '__globals__', 'X', 'y', 'Y', 'iAnn', 'Exp', 'idxtr', 'idxte'])
[7]:
X = Xdata['X']
# Xte = Xdata['Xte']
Y = Xdata['Y']
t = Xdata['y'].reshape(-1)
print('X',X.shape,'t',t.shape,'Y',Y.shape)
X (2310, 18) t (2310,) Y (2310, 5)
Labels Generation¶
[8]:
Y, iAnn, Lam_r = MA_Clas_Gen(X ,t, R=5, NrP=1)
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:780: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:790: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(

[9]:
Y = Y - 1
t = t - 1
[10]:
from sklearn.metrics import classification_report
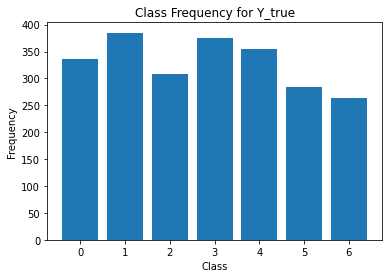
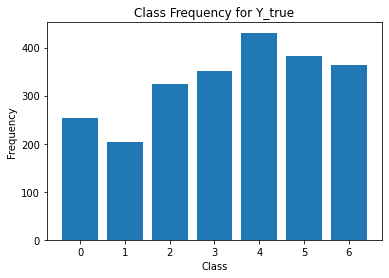
for i in range(Y.shape[1]):
print('annotator',i+1)
print(classification_report(t,Y[:,i]))
unique, counts = np.unique(Y[:,i], return_counts=True)
plt.figure()
plt.bar(unique, counts)
# unique, counts = np.unique(Y_test[5], return_counts=True)
# plt.bar(unique, counts)
plt.title('Class Frequency for Y_true')
plt.xlabel('Class')
plt.ylabel('Frequency')
annotator 1
precision recall f1-score support
0 0.83 0.85 0.84 330
1 0.86 1.00 0.92 330
2 0.83 0.78 0.80 330
3 0.86 0.98 0.92 330
4 0.84 0.91 0.87 330
5 0.87 0.75 0.81 330
6 0.87 0.69 0.77 330
accuracy 0.85 2310
macro avg 0.85 0.85 0.85 2310
weighted avg 0.85 0.85 0.85 2310
annotator 2
precision recall f1-score support
0 0.61 0.84 0.70 330
1 0.62 1.00 0.77 330
2 0.61 0.73 0.67 330
3 0.26 0.16 0.20 330
4 0.44 0.35 0.39 330
5 0.50 0.47 0.48 330
6 0.20 0.10 0.13 330
accuracy 0.52 2310
macro avg 0.46 0.52 0.48 2310
weighted avg 0.46 0.52 0.48 2310
annotator 3
precision recall f1-score support
0 0.73 0.41 0.52 330
1 0.82 0.98 0.89 330
2 0.67 0.42 0.52 330
3 0.75 0.79 0.77 330
4 0.78 0.78 0.78 330
5 0.79 1.00 0.88 330
6 0.77 1.00 0.87 330
accuracy 0.77 2310
macro avg 0.76 0.77 0.75 2310
weighted avg 0.76 0.77 0.75 2310
annotator 4
precision recall f1-score support
0 0.37 0.27 0.31 330
1 0.64 1.00 0.78 330
2 0.38 0.27 0.31 330
3 0.54 0.69 0.61 330
4 0.33 0.22 0.26 330
5 0.55 0.56 0.56 330
6 0.53 0.56 0.55 330
accuracy 0.51 2310
macro avg 0.48 0.51 0.48 2310
weighted avg 0.48 0.51 0.48 2310
annotator 5
precision recall f1-score support
0 0.18 0.14 0.15 330
1 0.00 0.00 0.00 330
2 0.16 0.16 0.16 330
3 0.27 0.28 0.28 330
4 0.46 0.60 0.52 330
5 0.38 0.44 0.41 330
6 0.40 0.44 0.42 330
accuracy 0.29 2310
macro avg 0.26 0.29 0.28 2310
weighted avg 0.26 0.29 0.28 2310



Split data¶
[11]:
import numpy.matlib
from sklearn.model_selection import ShuffleSplit, StratifiedShuffleSplit
Ns = 1
ss = ShuffleSplit(n_splits=Ns, test_size=0.3,random_state =123)
for train_index, test_index in ss.split(X):
print(test_index)
X_train, X_test,Y_train,Y_test = X[train_index,:], X[test_index,:],Y[train_index,:], Y[test_index,:]
Y_true_train, Y_true_test = t[train_index].reshape(-1,1), t[test_index].reshape(-1,1)
print(X_train.shape, Y_train.shape, Y_true_train.shape)
[2031 671 1207 1236 343 1158 822 558 18 1644 2044 2257 1440 1290
1758 2263 1422 1633 33 689 206 1380 2291 25 1652 961 279 2076
1777 995 1424 493 132 224 1278 1162 1121 1496 2303 327 1233 1631
417 1036 977 1708 2248 1204 803 711 856 50 2249 511 1567 1068
1725 12 2097 704 1667 1253 2041 965 1055 1237 2071 2165 1106 1873
2153 141 1860 1033 266 1661 1730 978 1614 813 1148 45 2045 2030
1181 1209 746 421 2197 1331 2034 875 1049 1404 1137 1851 683 809
515 1195 1256 2102 1018 967 476 1337 2170 1982 615 2177 388 1548
1744 110 835 2100 1126 1109 935 1802 1977 1797 668 820 190 1707
1542 1541 289 784 1446 1979 1903 326 292 420 798 239 1831 310
449 708 1201 2176 1449 72 982 800 2213 403 381 148 1531 601
466 2152 1676 351 1269 1412 728 1143 116 1790 1843 1818 658 1525
2308 1333 735 1059 777 1637 2243 1686 409 1697 1978 1516 1217 2304
1757 701 2266 120 680 1728 906 988 670 2179 375 1373 1913 1182
58 1250 2307 1951 842 383 1836 304 2253 1335 1127 1244 75 1090
1627 1324 1039 882 1589 1483 655 410 2113 833 1587 184 2012 1450
2118 1670 878 2221 1457 879 2110 1116 999 2290 2051 1358 429 103
1687 925 1224 649 1174 43 2115 698 1724 2126 1041 1234 1077 28
2174 440 1097 1089 243 2306 853 898 1295 1152 1806 1432 712 1423
1573 537 13 1035 1895 2279 2008 2064 228 2061 1042 1461 1469 198
498 1144 352 1074 1680 2025 63 458 569 1700 749 2088 917 1756
155 1330 1451 2210 188 1738 645 189 1185 1599 994 563 1441 2194
1603 1850 2278 1304 256 395 953 501 1205 1745 973 895 2204 406
1848 1781 827 1716 807 7 1711 1011 1455 1317 1829 1800 2277 276
127 1925 1009 1397 2287 1574 772 1577 1523 2150 1134 1727 1420 1742
778 1208 553 1762 108 524 237 1502 546 891 1436 1468 776 682
1020 1881 1202 1002 2128 579 641 328 1747 222 2142 785 1065 1616
1276 1416 1685 1572 605 477 1943 1079 963 1754 706 2085 1904 142
1043 1803 1313 1696 1785 564 1459 1266 1123 585 590 167 1027 2067
828 318 1000 1906 628 267 1361 1187 384 1600 787 1841 684 1354
2104 805 1102 1630 1390 1944 1907 1753 1096 610 1856 353 2112 273
633 1165 738 2151 742 1642 234 1334 500 356 556 21 990 937
1026 308 415 1634 1606 667 504 1805 433 574 1822 314 1003 597
838 593 452 1396 1285 846 529 235 270 229 2053 1773 5 934
1613 91 1456 1519 623 554 2191 221 890 1709 2158 427 1695 1220
2159 2222 1228 1921 781 1029 81 1809 968 437 1227 307 2229 2247
971 1014 1017 1561 1868 792 1701 1733 1821 926 64 996 265 182
630 638 1801 2224 722 928 1876 627 35 385 2062 616 2131 714
2268 1563 824 209 1899 1869 348 2300 1883 1504 1402 927 104 1302
2087 2189 278 119 618 2296 847 2250 1970 94 1935 591 1006 678
1260 779 1287 1426 1911 1816 576 1108 1515 2305 1340 1535 775 573
535 1464 1462 1681 1270 562 691 2178 1947 2005 756 594 1702 1665
216 31 131 1769 2136 66 734 1347 1582 204 2055 2184 1376 1878
1668 1553 1811 260 1499 1294 850 86 647 1638 2198 1643 2225 478
600 1526 717 2171 54 114 1142 1482 707 1289 1592 1046 312 1892
1584 831 2125 218 1369 767 250 1274 450 1327 2021 2072 1712 397
533 1780 1549 614 1706 1356 1216 550 1595 2223 1569 710 1050 1001
1671 42 857 277 372 112 147 1886 226 178 1588 1787 1663 1188
336 991 1023 1094 2111 309 301 2216 2003 306 84 547 261 565
905 357 1763 1992 914 1351 1528]
(1617, 18) (1617, 5) (1617, 1)
Apply MinMaxScaler¶
[12]:
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Testing the Class¶
[13]:
from sklearn.metrics import classification_report, balanced_accuracy_score, roc_auc_score
from sklearn.metrics import normalized_mutual_info_score, mutual_info_score, adjusted_mutual_info_score
l1 =0.001
NUM_RUNS =10
ACC = np.zeros(NUM_RUNS)
AUC = np.zeros(NUM_RUNS)
AUCSK = np.zeros(NUM_RUNS)
MI = np.zeros(NUM_RUNS)
NMI = np.zeros(NUM_RUNS)
AMI = np.zeros(NUM_RUNS)
BACC = np.zeros(NUM_RUNS)
for i in range(NUM_RUNS): #10
print("iteration: " + str(i))
MA = Keras_MA_GCCE(epochs=100,batch_size=32,R=5, K=len(np.unique(Y_true_train)), dropout=0.25, learning_rate=0.001,optimizer='Adam',
l1_param=l1, validation_split=0.30, verbose=0, q=0.3, neurons=4)
MA.fit(X_train, Y_train)
MA.plot_history()
#Accuracy
pred_2 = MA.predict(X_test)
report = classification_report( pred_2[:,Y.shape[1]:].argmax(axis=1),Y_true_test.ravel(),output_dict=True)
ACC[i] = report['accuracy']
print("Validation ACC: %.4f" % (float(ACC[i])))
# balanced. Accurcy
BACC[i] = balanced_accuracy_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze(), adjusted=True)
print("Validation Balanced_ACC: %.4f" % (float(BACC[i])))
#MI
MI[i] = mutual_info_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze())
print("Validation MI: %.4f" % (float(MI[i]),))
NMI[i] = normalized_mutual_info_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze())
print("Validation Normalized MI: %.4f" % (float(NMI[i]),))
AMI[i]= adjusted_mutual_info_score(Y_true_test.squeeze(), pred_2[:,Y.shape[1]:].argmax(axis=1).squeeze())
print("Validation Adjusted MI: %.4f" % (float(AMI[i]),))
#AUC
val_AUC_metric = tf.keras.metrics.AUC( from_logits = True)
# val_logits =MA.predict(X_test) # model(X_test, training=False)
# tf.print(y_batch_val)
val_AUC_metric.update_state(Y_true_test, pred_2[:,Y.shape[1]:].argmax(axis=1).astype('float'))
val_AUC = val_AUC_metric.result()
val_AUC_metric.reset_states()
val_AUC = val_AUC.numpy()
print("Validation aUc: %.4f" % (float(val_AUC),))
AUC[i] = val_AUC
val_AUC1 = roc_auc_score(ook(Y_true_test), pred_2[:,Y_train.shape[1]:])
print("Validation aUc_Sklearn: %.4f" % (float(val_AUC1),))
AUCSK[i] = val_AUC1
iteration: 0
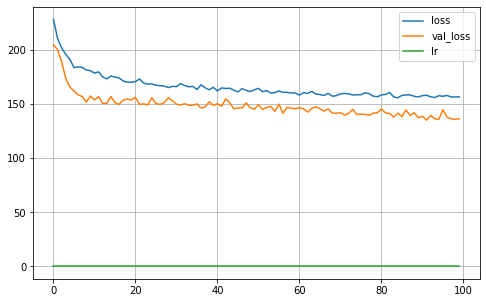
22/22 [==============================] - 0s 3ms/step
Validation ACC: 0.9048
Validation Balanced_ACC: 0.8914
Validation MI: 1.6543
Validation Normalized MI: 0.8513
Validation Adjusted MI: 0.8492
Validation aUc: 0.9950
Validation aUc_Sklearn: 0.9935
iteration: 1
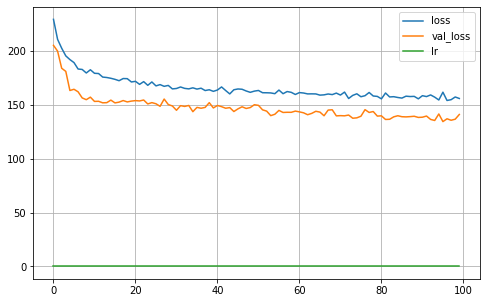
22/22 [==============================] - 0s 3ms/step
Validation ACC: 0.8961
Validation Balanced_ACC: 0.8826
Validation MI: 1.6419
Validation Normalized MI: 0.8503
Validation Adjusted MI: 0.8483
Validation aUc: 0.9945
Validation aUc_Sklearn: 0.9936
iteration: 2

22/22 [==============================] - 0s 2ms/step
Validation ACC: 0.9019
Validation Balanced_ACC: 0.8888
Validation MI: 1.6348
Validation Normalized MI: 0.8416
Validation Adjusted MI: 0.8394
Validation aUc: 0.9925
Validation aUc_Sklearn: 0.9935
iteration: 3
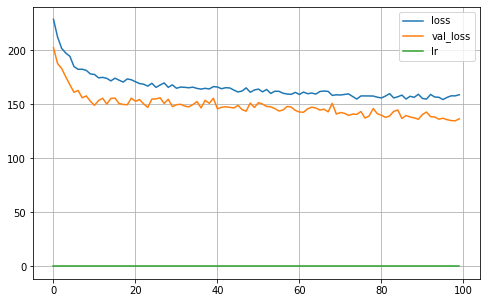
22/22 [==============================] - 0s 2ms/step
Validation ACC: 0.9192
Validation Balanced_ACC: 0.9085
Validation MI: 1.6883
Validation Normalized MI: 0.8710
Validation Adjusted MI: 0.8692
Validation aUc: 0.9941
Validation aUc_Sklearn: 0.9953
iteration: 4
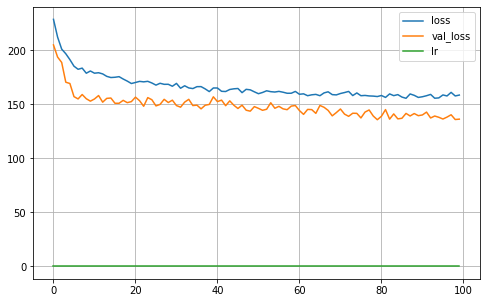
22/22 [==============================] - 0s 2ms/step
Validation ACC: 0.9351
Validation Balanced_ACC: 0.9268
Validation MI: 1.7100
Validation Normalized MI: 0.8796
Validation Adjusted MI: 0.8780
Validation aUc: 0.9966
Validation aUc_Sklearn: 0.9954
iteration: 5
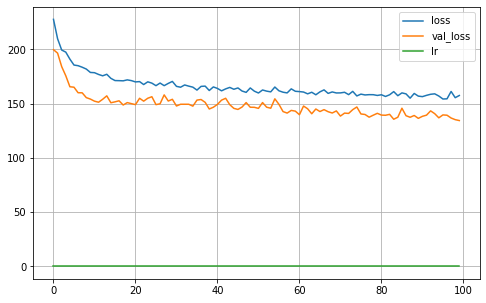
22/22 [==============================] - 0s 2ms/step
Validation ACC: 0.9163
Validation Balanced_ACC: 0.9045
Validation MI: 1.6877
Validation Normalized MI: 0.8711
Validation Adjusted MI: 0.8693
Validation aUc: 0.9966
Validation aUc_Sklearn: 0.9950
iteration: 6
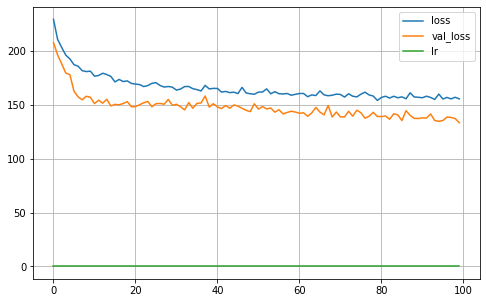
22/22 [==============================] - 0s 3ms/step
Validation ACC: 0.9177
Validation Balanced_ACC: 0.9060
Validation MI: 1.6711
Validation Normalized MI: 0.8596
Validation Adjusted MI: 0.8577
Validation aUc: 0.9718
Validation aUc_Sklearn: 0.9942
iteration: 7

22/22 [==============================] - 0s 4ms/step
Validation ACC: 0.9062
Validation Balanced_ACC: 0.8932
Validation MI: 1.6773
Validation Normalized MI: 0.8677
Validation Adjusted MI: 0.8659
Validation aUc: 0.9941
Validation aUc_Sklearn: 0.9943
iteration: 8
22/22 [==============================] - 0s 4ms/step
Validation ACC: 0.9076
Validation Balanced_ACC: 0.8953
Validation MI: 1.6586
Validation Normalized MI: 0.8554
Validation Adjusted MI: 0.8534
Validation aUc: 0.9660
Validation aUc_Sklearn: 0.9922
iteration: 9

22/22 [==============================] - 0s 3ms/step
Validation ACC: 0.9004
Validation Balanced_ACC: 0.8864
Validation MI: 1.6492
Validation Normalized MI: 0.8492
Validation Adjusted MI: 0.8472
Validation aUc: 0.9940
Validation aUc_Sklearn: 0.9932
[14]:
ACC
[14]:
array([0.9047619 , 0.8961039 , 0.9018759 , 0.91919192, 0.93506494,
0.91630592, 0.91774892, 0.90620491, 0.90764791, 0.9004329 ])
[15]:
AUC
[15]:
array([0.99497485, 0.99451244, 0.99246228, 0.99413735, 0.99664992,
0.99664116, 0.97183836, 0.99413735, 0.96602803, 0.99395412])
[16]:
print('Average Accuracy: ', np.round( ACC.mean(),4)*100)
print('Average std: ',np.round(np.std( ACC),4)*100)
Average Accuracy: 91.05
Average std: 1.0999999999999999
[17]:
print('Average AUC: ', np.round( AUC.mean(),4)*100)
print('Average AUC std: ',np.round(np.std( AUC),4)*100)
Average AUC: 98.95
Average AUC std: 1.04
[18]:
print('Average Accuracy: ', np.round( ACC.mean(),4)*100)
print('Average std: ',np.round(np.std( ACC),4)*100)
print('==============================================')
print('Average AUC: ', np.round( AUC.mean(),4)*100)
print('Average AUC std: ',np.round(np.std( AUC),4)*100)
print('==============================================')
print('Average AUC Sklearn: ', np.round( AUCSK.mean(),4)*100)
print('Average AUC SK std: ',np.round(np.std( AUCSK),4)*100)
print('==============================================')
print('Average Balanced Accuracy: ', np.round( BACC.mean(),4)*100)
print('Average std: ',np.round(np.std( BACC),4)*100)
print('==============================================')
print('Average MI: ', np.round( MI.mean(),4)*100)
print('Average std: ',np.round(np.std(MI),4)*100)
print('==============================================')
print('Average Normalized MI: ', np.round( NMI.mean(),4)*100)
print('Average std: ',np.round(np.std(NMI),4)*100)
print('==============================================')
print('Average Ajdusted MI: ', np.round( AMI.mean(),4)*100)
print('Average std: ',np.round(np.std(AMI),4)*100)
Average Accuracy: 91.05
Average std: 1.0999999999999999
==============================================
Average AUC: 98.95
Average AUC std: 1.04
==============================================
Average AUC Sklearn: 99.4
Average AUC SK std: 0.1
==============================================
Average Balanced Accuracy: 89.83
Average std: 1.25
==============================================
Average MI: 166.73
Average std: 2.25
==============================================
Average Normalized MI: 85.97
Average std: 1.15
==============================================
Average Ajdusted MI: 85.77
Average std: 1.17
[19]:
import pickle
# create the dictionary with 6 scalar variables
Metrics = {
'Accuracy': np.round( ACC.mean(),4)*100,
'Accuracy_std': np.round(np.std( ACC),4)*100,
'AUC': np.round( AUC.mean(),4)*100,
'AUC_std': np.round(np.std( AUC),4)*100,
'AUCSK': np.round( AUCSK.mean(),4)*100,
'AUCSK_std': np.round(np.std( AUCSK),4)*100,
'Balanced Accuracy': np.round( BACC.mean(),4)*100,
'Balanced Accuracy_std': np.round(np.std(BACC),4)*100,
'MI': np.round( MI.mean(),4)*100,
'MI_std': np.round(np.std(MI),4)*100,
'Normalized MI': np.round( NMI.mean(),4)*100,
'Normalized MI_std': np.round(np.std(NMI),4)*100,
'Adjusted MI': np.round( AMI.mean(),4)*100,
'Adjusted MI_std': np.round(np.std(NMI),4)*100,
}
# save the dictionary to a file using pickle
with open('data.pickle', 'wb') as handle:
pickle.dump(Metrics, handle, protocol=pickle.HIGHEST_PROTOCOL)
Metrics
[19]:
{'Accuracy': 91.05,
'Accuracy_std': 1.0999999999999999,
'AUC': 98.95,
'AUC_std': 1.04,
'AUCSK': 99.4,
'AUCSK_std': 0.1,
'Balanced Accuracy': 89.83,
'Balanced Accuracy_std': 1.25,
'MI': 166.73,
'MI_std': 2.25,
'Normalized MI': 85.97,
'Normalized MI_std': 1.15,
'Adjusted MI': 85.77,
'Adjusted MI_std': 1.15}