![]()
[1]:
#!pip install tensorflow==2.7.0
#!pip install scikeras
[2]:
import tensorflow as tf
from sklearn.metrics import classification_report, accuracy_score, balanced_accuracy_score, roc_auc_score, mutual_info_score, normalized_mutual_info_score, adjusted_mutual_info_score
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import mode
import numpy as np
def ook(t):
lb = LabelBinarizer()
y_ook = lb.fit_transform(t)
if len(np.unique(t))==2:
y_ook = np.concatenate((1-y_ook.astype(bool), y_ook), axis = 1)
return y_ook
def evaluation_metrics(y_true, y_pred, print_result=True):
acc = 0
auc = 0
auc_sk = 0
#mi = 0
nmi = 0
#ami = 0
bacc = 0
# Accuracy
#report = classification_report(y_pred.argmax(axis=1), y_true.ravel(), output_dict=True)
acc = accuracy_score( y_true.ravel(), y_pred.argmax(axis=1)) #report['accuracy']
# Balanced accuracy
bacc = balanced_accuracy_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze(), adjusted=True)
# # Mutual Information
# mi = mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Normalized Mutual Information
nmi = normalized_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# Adjusted Mutual Information
#ami = adjusted_mutual_info_score(y_true.squeeze(), y_pred.argmax(axis=1).squeeze())
# AUC (Tensorflow)
auc_metric = tf.keras.metrics.AUC(from_logits=True)
auc_metric.update_state(y_true, y_pred.argmax(axis=1).astype('float'))
auc = auc_metric.result().numpy()
auc_metric.reset_states()
# AUC (scikit-learn)
auc_sk = roc_auc_score(ook(y_true), y_pred)
if print_result:
print("Accuracy: {:.4f}".format(acc))
print("Balanced Accuracy: {:.4f}".format(bacc))
print("Mutual Information: {:.4f}".format(mi))
print("Normalized Mutual Information: {:.4f}".format(nmi))
print("Adjusted Mutual Information: {:.4f}".format(ami))
print("AUC (Tensorflow): {:.4f}".format(auc))
print("AUC (scikit-learn): {:.4f}".format(auc_sk))
return acc, auc, auc_sk, nmi, bacc # mi, , ami
[3]:
!git clone https://github.com/Jectrianama/GCCE_TEST.git
Cloning into 'GCCE_TEST'...
remote: Enumerating objects: 865, done.
remote: Counting objects: 100% (458/458), done.
remote: Compressing objects: 100% (242/242), done.
remote: Total 865 (delta 241), reused 397 (delta 210), pack-reused 407
Receiving objects: 100% (865/865), 38.98 MiB | 12.33 MiB/s, done.
Resolving deltas: 100% (409/409), done.
Updating files: 100% (149/149), done.
[4]:
import os
os.chdir('/content/GCCE_TEST/Models')
from keras_ma_gcce import *
from labels_generation import MA_Clas_Gen
os.chdir('../../')
Subclassing for RCDNN¶
[5]:
#cargar datos desde drive otros dataset
FILEID = "1AU8pTtCLihBjCZjWITaAzpnEuL4RO436"
#https://drive.google.com/file/d/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O DataGCCE.zip && rm -rf /tmp/cookies.txt
!unzip -o DataGCCE.zip
!dir
--2023-02-13 17:38:12-- https://docs.google.com/uc?export=download&confirm=&id=1AU8pTtCLihBjCZjWITaAzpnEuL4RO436
Resolving docs.google.com (docs.google.com)... 142.251.16.100, 142.251.16.113, 142.251.16.139, ...
Connecting to docs.google.com (docs.google.com)|142.251.16.100|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ho5ppsisc7n1e7m0dglmiir9ndd47h2j/1676309850000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=07358ca9-0c8c-4308-a12f-4ad93f4afb58 [following]
Warning: wildcards not supported in HTTP.
--2023-02-13 17:38:13-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ho5ppsisc7n1e7m0dglmiir9ndd47h2j/1676309850000/07591141114418430227/*/1AU8pTtCLihBjCZjWITaAzpnEuL4RO436?e=download&uuid=07358ca9-0c8c-4308-a12f-4ad93f4afb58
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 172.253.62.132, 2607:f8b0:4004:c07::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|172.253.62.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 38377 (37K) [application/x-zip-compressed]
Saving to: ‘DataGCCE.zip’
DataGCCE.zip 100%[===================>] 37.48K --.-KB/s in 0s
2023-02-13 17:38:13 (78.3 MB/s) - ‘DataGCCE.zip’ saved [38377/38377]
Archive: DataGCCE.zip
inflating: new-thyroid.csv
inflating: tic-tac-toe-endgame.csv
inflating: balance-scale.csv
inflating: file.csv
balance-scale.csv file.csv new-thyroid.csv tic-tac-toe-endgame.csv
DataGCCE.zip GCCE_TEST sample_data
[6]:
#cargar datos desde drive acceso libre
FILEID = "1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW"
#https://drive.google.com/file/d/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW/view?usp=sharing
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='$FILEID -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id="$FILEID -O MADatasets.zip && rm -rf /tmp/cookies.txt
!unzip -o MADatasets.zip
!dir
--2023-02-13 17:38:14-- https://docs.google.com/uc?export=download&confirm=t&id=1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW
Resolving docs.google.com (docs.google.com)... 142.251.16.100, 142.251.16.113, 142.251.16.139, ...
Connecting to docs.google.com (docs.google.com)|142.251.16.100|:443... connected.
HTTP request sent, awaiting response... 303 See Other
Location: https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ticufmsgdo05mnl740es3o8dinm0qrcl/1676309850000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=06826a33-dcf6-4a8b-848f-3cda7efdea0c [following]
Warning: wildcards not supported in HTTP.
--2023-02-13 17:38:14-- https://doc-00-90-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/ticufmsgdo05mnl740es3o8dinm0qrcl/1676309850000/07591141114418430227/*/1SQnWXGROG2Xexs5vn3twuv7SqiWG5njW?e=download&uuid=06826a33-dcf6-4a8b-848f-3cda7efdea0c
Resolving doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)... 172.253.62.132, 2607:f8b0:4004:c07::84
Connecting to doc-00-90-docs.googleusercontent.com (doc-00-90-docs.googleusercontent.com)|172.253.62.132|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 156530728 (149M) [application/zip]
Saving to: ‘MADatasets.zip’
MADatasets.zip 100%[===================>] 149.28M 59.8MB/s in 2.5s
2023-02-13 17:38:17 (59.8 MB/s) - ‘MADatasets.zip’ saved [156530728/156530728]
Archive: MADatasets.zip
inflating: MADatasets/util.py
inflating: MADatasets/Iris1.mat
inflating: MADatasets/Integra_Labels.mat
inflating: MADatasets/MAGenerationClassification.py
inflating: MADatasets/Voice.mat
inflating: MADatasets/Iris.mat
inflating: MADatasets/Sinthetic.mat
inflating: MADatasets/MAGenerationClassification_1.py
inflating: MADatasets/Bupa1.mat
inflating: MADatasets/TicTacToe1.mat
inflating: MADatasets/Wine.mat
inflating: MADatasets/Breast1.mat
inflating: MADatasets/Breast.mat
inflating: MADatasets/Music.mat
inflating: MADatasets/Pima.mat
inflating: MADatasets/Ionosphere.mat
inflating: MADatasets/TicTacToe.mat
inflating: MADatasets/VoiceData.m
inflating: MADatasets/util_1.py
inflating: MADatasets/Ionosphere1.mat
inflating: MADatasets/__pycache__/util_1.cpython-37.pyc
inflating: MADatasets/Bupa.mat
inflating: MADatasets/Wine1.mat
inflating: MADatasets/__pycache__/util.cpython-37.pyc
inflating: MADatasets/Pima1.mat
inflating: MADatasets/Segmentation1.mat
inflating: MADatasets/Western.mat
inflating: MADatasets/Integra_Preprocesamiento_Seg_Caracterizacion_time_frec.mat
inflating: MADatasets/Western1.mat
inflating: MADatasets/Segmentation.mat
inflating: MADatasets/Skin_NonSkin.mat
inflating: MADatasets/Skin_NonSkin1.mat
inflating: MADatasets/Occupancy1.mat
inflating: MADatasets/Polarity.mat
inflating: MADatasets/Occupancy.mat
balance-scale.csv GCCE_TEST new-thyroid.csv
DataGCCE.zip MADatasets sample_data
file.csv MADatasets.zip tic-tac-toe-endgame.csv
Load Data¶
[7]:
#load data
import scipy.io as sio
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf #importar tensorflow
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import numpy as np
database = 'Iris' #['bupa1', 'breast-cancer-wisconsin1','pima-indians-diabetes1', 'ionosphere1', 'tic-tac-toe1', 'iris1', 'wine1', 'segmentation1']
path_ = 'MADatasets/'+ database+ '.mat'
Xdata = sio.loadmat(path_)
Xdata.keys()
[7]:
dict_keys(['__header__', '__version__', '__globals__', 'X', 'y', 'Y', 'iAnn', 'Exp', 'idxtr', 'idxte'])
[8]:
X = Xdata['X']
# Xte = Xdata['Xte']
Y = Xdata['Y']
t = Xdata['y'].reshape(-1)
print('X',X.shape,'t',t.shape,'Y',Y.shape)
X (150, 4) t (150,) Y (150, 5)
Labels Generation¶
[9]:
Y, iAnn, Lam_r = MA_Clas_Gen(X ,t, R=5, NrP=1)
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:780: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/sklearn/manifold/_t_sne.py:790: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(

[10]:
Y = Y - 1
t = t - 1
#YMA = YMA-1
[11]:
from sklearn.metrics import classification_report
for i in range(Y.shape[1]):
print('annotator',i+1)
print(classification_report(t,Y[:,i]))
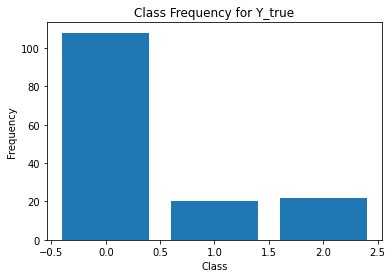
unique, counts = np.unique(Y[:,i], return_counts=True)
plt.figure()
plt.bar(unique, counts)
# unique, counts = np.unique(Y_test[5], return_counts=True)
# plt.bar(unique, counts)
plt.title('Class Frequency for Y_true')
plt.xlabel('Class')
plt.ylabel('Frequency')
annotator 1
precision recall f1-score support
0 1.00 1.00 1.00 50
1 1.00 1.00 1.00 50
2 1.00 1.00 1.00 50
accuracy 1.00 150
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150
annotator 2
precision recall f1-score support
0 0.00 0.00 0.00 50
1 0.62 1.00 0.76 50
2 0.71 0.98 0.82 50
accuracy 0.66 150
macro avg 0.44 0.66 0.53 150
weighted avg 0.44 0.66 0.53 150
annotator 3
precision recall f1-score support
0 0.53 0.98 0.69 50
1 0.14 0.06 0.08 50
2 0.37 0.26 0.31 50
accuracy 0.43 150
macro avg 0.34 0.43 0.36 150
weighted avg 0.34 0.43 0.36 150
annotator 4
precision recall f1-score support
0 0.00 0.00 0.00 50
1 0.21 0.12 0.15 50
2 0.47 0.96 0.63 50
accuracy 0.36 150
macro avg 0.22 0.36 0.26 150
weighted avg 0.22 0.36 0.26 150
annotator 5
precision recall f1-score support
0 0.46 1.00 0.63 50
1 0.00 0.00 0.00 50
2 0.00 0.00 0.00 50
accuracy 0.33 150
macro avg 0.15 0.33 0.21 150
weighted avg 0.15 0.33 0.21 150
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))




Split data¶
[12]:
import numpy.matlib
from sklearn.model_selection import ShuffleSplit, StratifiedShuffleSplit
Ns = 1
ss = ShuffleSplit(n_splits=Ns, test_size=0.3,random_state =123)
for train_index, test_index in ss.split(X):
print(test_index)
X_train, X_test,Y_train,Y_test = X[train_index,:], X[test_index,:],Y[train_index,:], Y[test_index,:]
Y_true_train, Y_true_test = t[train_index].reshape(-1,1), t[test_index].reshape(-1,1)
print(X_train.shape, Y_train.shape, Y_true_train.shape)
[ 72 112 132 88 37 138 87 42 8 90 141 33 59 116 135 104 36 13
63 45 28 133 24 127 46 20 31 121 117 4 130 119 29 0 62 93
131 5 16 82 60 35 143 145 142]
(105, 4) (105, 5) (105, 1)
Apply MinMaxScaler¶
[13]:
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Testing the Class¶
[14]:
from sklearn.metrics import classification_report, balanced_accuracy_score, roc_auc_score
from sklearn.metrics import normalized_mutual_info_score, mutual_info_score, adjusted_mutual_info_score
import pandas as pd
l1 =0.0001
NUM_RUNS =10
custom_loss = "GCE"
results = []
for i in range(NUM_RUNS):
print("iteration: " + str(i))
MA = Keras_MA_GCCE(epochs=100,batch_size=32,R=5, K=len(np.unique(Y_true_train)), dropout=0.2, learning_rate=0.001,optimizer='Adam',
l1_param=l1, validation_split=0, verbose=0, q=0.3, neurons=4, loss = custom_loss )
MA.fit(X_train, Y_train)
MA.plot_history()
# Generate the predictions for the current run
pred_2 = MA.predict(X_test)
acc, auc, auc_sk, nmi, bacc = evaluation_metrics(Y_true_test, pred_2[:,Y.shape[1]:], print_result=False) # mi, ami,
# Save the results for the current run to the list of dictionaries
results.append({
#'run': i,
'accuracy': acc,
'balanced_accuracy': bacc,
# 'mutual_information': mi,
'normalized_mutual_information': nmi,
# 'adjusted_mutual_information': ami,
'auc_tensorflow': auc,
'auc_scikit_learn': auc_sk,
})
# Convert the list of dictionaries to a DataFrame
df = np.round(pd.DataFrame(results)*100, 2)
# Calculate the mean and standard deviation of each metric
mean = np.round(df.mean(),2)
std = np.round(df.std(),2)
iteration: 0

2/2 [==============================] - 0s 6ms/step
iteration: 1

2/2 [==============================] - 0s 5ms/step
iteration: 2
2/2 [==============================] - 0s 7ms/step
iteration: 3
2/2 [==============================] - 0s 5ms/step
iteration: 4
WARNING:tensorflow:5 out of the last 9 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f32c5f8aa60> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
2/2 [==============================] - 0s 6ms/step
iteration: 5
WARNING:tensorflow:6 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f32c691ba60> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
2/2 [==============================] - 0s 7ms/step
iteration: 6
2/2 [==============================] - 0s 5ms/step
iteration: 7

2/2 [==============================] - 0s 6ms/step
iteration: 8

2/2 [==============================] - 0s 4ms/step
iteration: 9

2/2 [==============================] - 0s 5ms/step
[15]:
df
[15]:
| accuracy | balanced_accuracy | normalized_mutual_information | auc_tensorflow | auc_scikit_learn | |
|---|---|---|---|---|---|
| 0 | 95.56 | 92.06 | 85.33 | 100.0 | 99.83 |
| 1 | 97.78 | 97.06 | 92.60 | 100.0 | 99.67 |
| 2 | 97.78 | 97.06 | 92.60 | 100.0 | 99.83 |
| 3 | 97.78 | 97.06 | 92.60 | 100.0 | 99.67 |
| 4 | 95.56 | 92.06 | 85.33 | 100.0 | 99.67 |
| 5 | 97.78 | 97.06 | 92.60 | 100.0 | 99.67 |
| 6 | 97.78 | 97.06 | 92.60 | 100.0 | 99.67 |
| 7 | 97.78 | 97.06 | 92.60 | 100.0 | 99.83 |
| 8 | 97.78 | 97.06 | 92.60 | 100.0 | 99.67 |
| 9 | 97.78 | 97.06 | 92.60 | 100.0 | 99.67 |
[16]:
mean
[16]:
accuracy 97.34
balanced_accuracy 96.06
normalized_mutual_information 91.15
auc_tensorflow 100.00
auc_scikit_learn 99.72
dtype: float64
[17]:
std
[17]:
accuracy 0.94
balanced_accuracy 2.11
normalized_mutual_information 3.07
auc_tensorflow 0.00
auc_scikit_learn 0.08
dtype: float64
[18]:
result_df = pd.concat([mean.rename('Mean'), std.rename('Std')], axis=1)
[19]:
result_df
[19]:
| Mean | Std | |
|---|---|---|
| accuracy | 97.34 | 0.94 |
| balanced_accuracy | 96.06 | 2.11 |
| normalized_mutual_information | 91.15 | 3.07 |
| auc_tensorflow | 100.00 | 0.00 |
| auc_scikit_learn | 99.72 | 0.08 |
[20]:
# Save the DataFrame to an excel file
result_df.to_excel(database + custom_loss + ".xlsx")